RocksDB选择了无锁化的策略控制并发,做法是把写请求缓存,选出leader线程作为代表统一进行写请求提交。
1 线程缓冲区 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 bool WriteThread::LinkOne (Writer* w, std::atomic<Writer*>* newest_writer) assert (newest_writer != nullptr );assert (w->state == STATE_INIT); load (std::memory_order_relaxed);while (true ) {assert (writers != w);if (writers == &write_stall_dummy_) {if (w->no_slowdown) {Incomplete ("Write stall" );SetState (w, STATE_COMPLETED);return false ;MutexLock lock (&stall_mu_) ;load (std::memory_order_relaxed);if (writers == &write_stall_dummy_) {TEST_SYNC_POINT_CALLBACK ("WriteThread::WriteStall::Wait" , w);Wait ();load (std::memory_order_relaxed);continue ;if (newest_writer->compare_exchange_weak (writers, w)) {return (writers == nullptr );
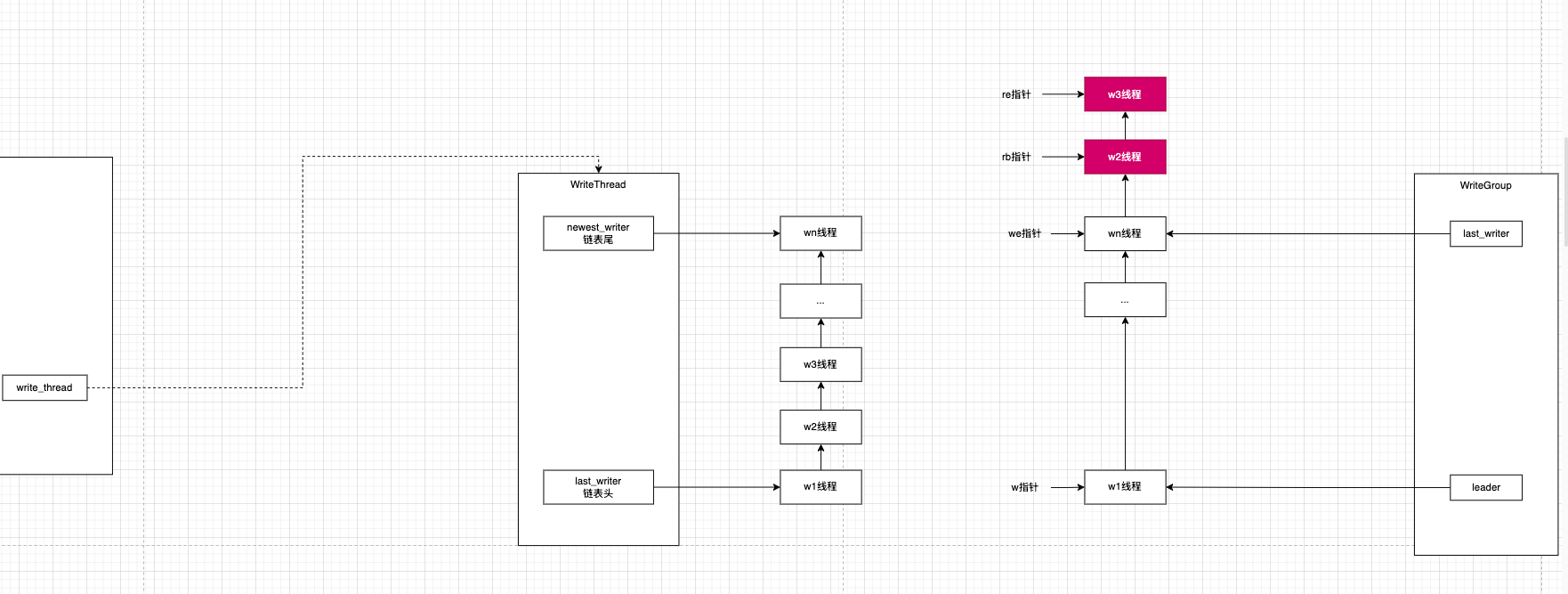
2 竞选leader RocksDB把每个写线程都封装成Writer,然后用WriteThead对这些所有线程进行统一管理。链表管理线程采用头插,能晋选leader的是链表的尾结点上的线程。
3 Leader收集Group Leader的职责是进行批处理,所以前提是Leader需要先识别出来哪些写线程请求算是一批的,抽象了WriteGroup用来表达集中处理的批。
3.1 WriteGroup结构 1 2 3 4 5 6 7 struct WriteGroup {nullptr ;nullptr ;
3.2 Leader怎么收集WriteGroup 单纯指针操作
3.2.1 不能批处理的单独放到临时队列 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 if (w->link_newer != nullptr ) {if (re == nullptr ) {nullptr ;else {
3.2.2 能批处理的交给Group 1 2 3 4 5 6 7 ByteSize (w->batch);
3.2.3 依然保证所有线程时序 1 2 3 4 5 6 7 8 9 10 11 12 if (rb != nullptr ) {nullptr ;if (!newest_writer_.compare_exchange_weak (w, re)) {while (w->link_older != newest_writer) {
4 数据汇总 现在Group里面[leader…last_writer]区间是要提交的数据,要把这些数据汇总起来放到一起
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 for (auto writer : write_group) {if (!writer->CallbackFailed ()) {Append (*merged_batch, writer->batch,true );if (!s.ok ()) {Clear ();return s;if (WriteBatchInternal::IsLatestPersistentState (writer->batch)) {
5 一次性写到WAL 先从WriteBatch协议中拿到二进制格式
1 2 Contents (&merged_batch);
然后把二进制数据写到WAL
1 2 AddRecord (write_options, log_entry, sequence);
6 写到内存缓冲表 这个地方用到了经典的回调方式来解耦
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 Status WriteBatch::Iterate (Handler* handler) const {if (rep_.size () < WriteBatchInternal::kHeader) {return Status::Corruption ("malformed WriteBatch (too small)" );return WriteBatchInternal::Iterate (this , handler, WriteBatchInternal::kHeader,size ());
真正把数据写到内存表的实现是class MemTableInserter : public WriteBatch::Handler