if lastIndex != 0 { // 这个地方为什么要这样校验呢 因为能调用这个方法的地方只有一个 就是raft启动时候节点机器是干净的 没有snap 也没有wal 需要手工造日志entry 让后面的选主流程能走下去 return errors.New("can't bootstrap a nonempty Storage") }
// We've faked out initial entries above, but nothing has been // persisted. Start with an empty HardState (thus the first Ready will // emit a HardState update for the app to persist). rn.prevHardSt = emptyState
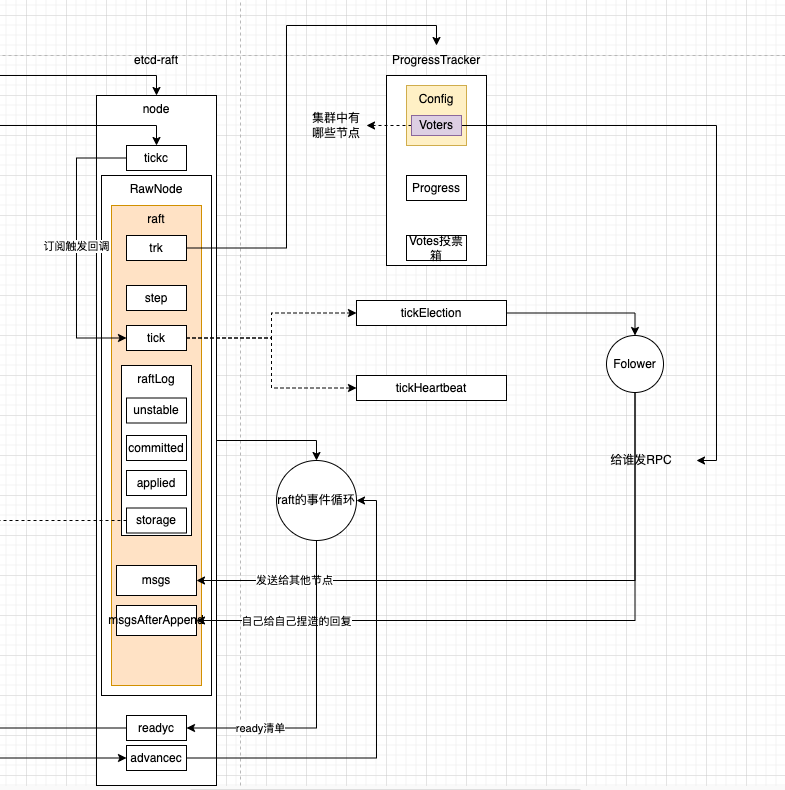
// TODO(tbg): remove StartNode and give the application the right tools to // bootstrap the initial membership in a cleaner way. // 角色初始化为Follower 为什么是Follower 因为心跳超时事件后发现自己是Follower就会触发选主 rn.raft.becomeFollower(1, None) // 集群的配置 模拟成RPC 既然是模拟 这个地方就假装收到了Leader的AppendEntries就行 // 下面就模拟收到AppendEntries的候选流程先放到unstable中 因为是模拟的 所以并不需要对这些模拟的RPC进行回复 直接commit然后应用到raft状态机 ents := make([]pb.Entry, len(peers)) for i, peer := range peers { cc := pb.ConfChange{Type: pb.ConfChangeAddNode, NodeID: peer.ID, Context: peer.Context} data, err := cc.Marshal() if err != nil { return err }
// Now apply them, mainly so that the application can call Campaign // immediately after StartNode in tests. Note that these nodes will // be added to raft twice: here and when the application's Ready // loop calls ApplyConfChange. The calls to addNode must come after // all calls to raftLog.append so progress.next is set after these // bootstrapping entries (it is an error if we try to append these // entries since they have already been committed). // We do not set raftLog.applied so the application will be able // to observe all conf changes via Ready.CommittedEntries. // // TODO(bdarnell): These entries are still unstable; do we need to preserve // the invariant that committed < unstable? // 模拟这些日志被集群大多数节点认可 也就是直接commit就行 rn.raft.raftLog.committed = uint64(len(ents)) for _, peer := range peers { // 应用到状态机 这边就会轮询把集群中节点都加到Voters中 rn.raft.applyConfChange(pb.ConfChange{NodeID: peer.ID, Type: pb.ConfChangeAddNode}.AsV2()) } returnnil }