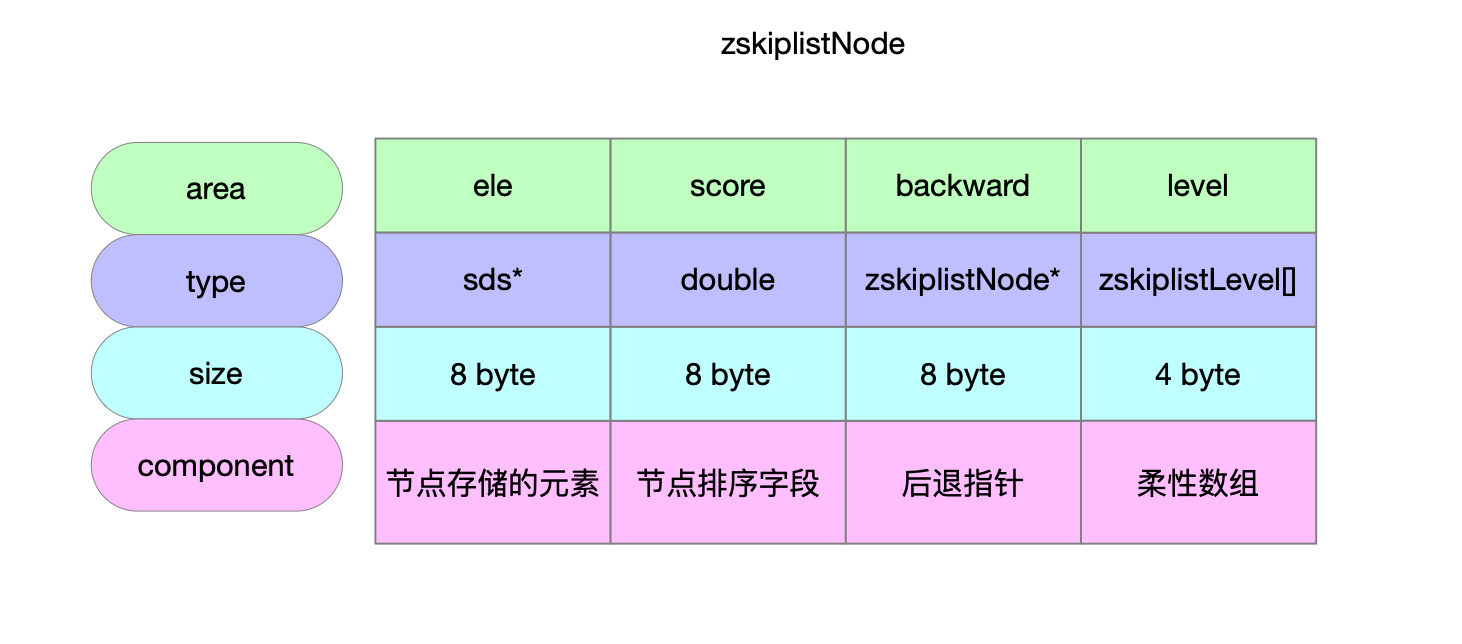
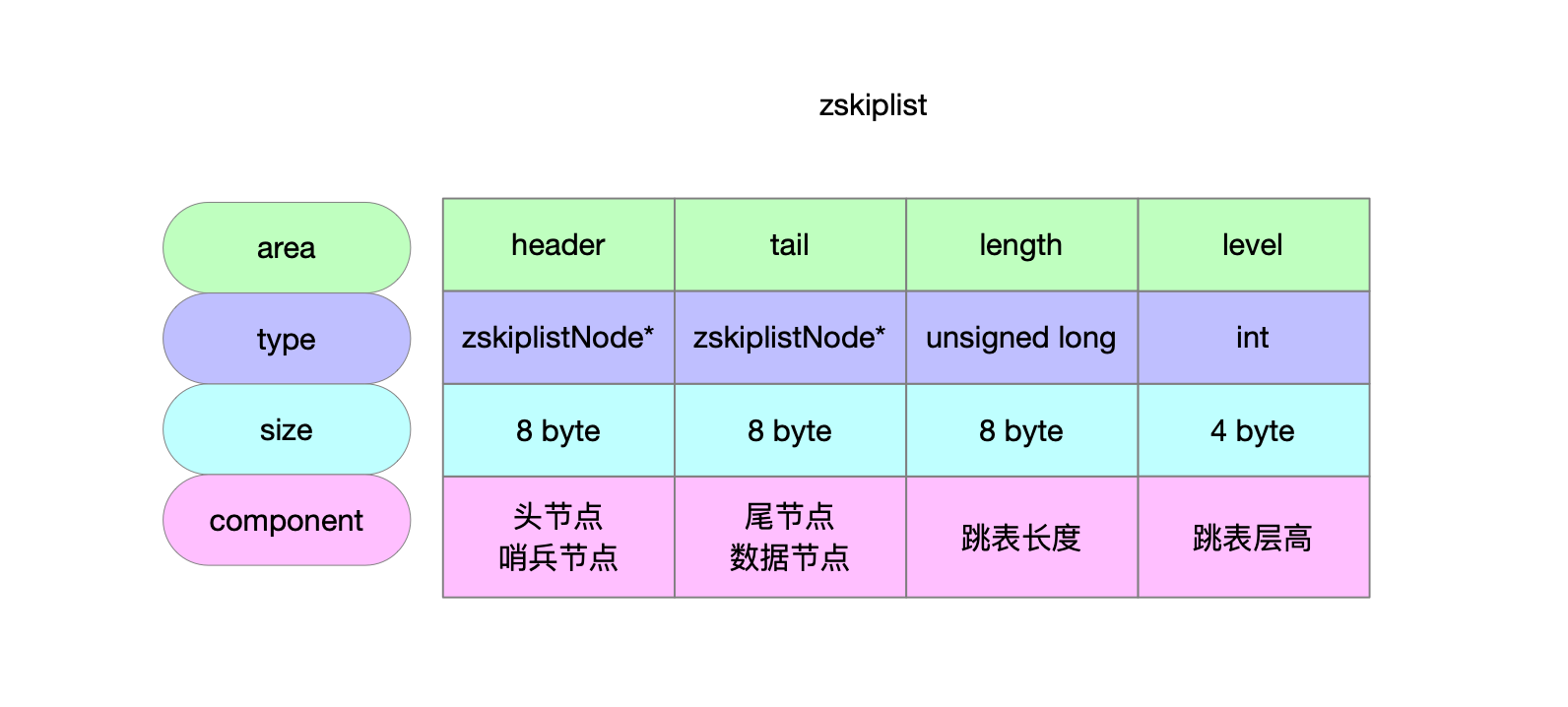
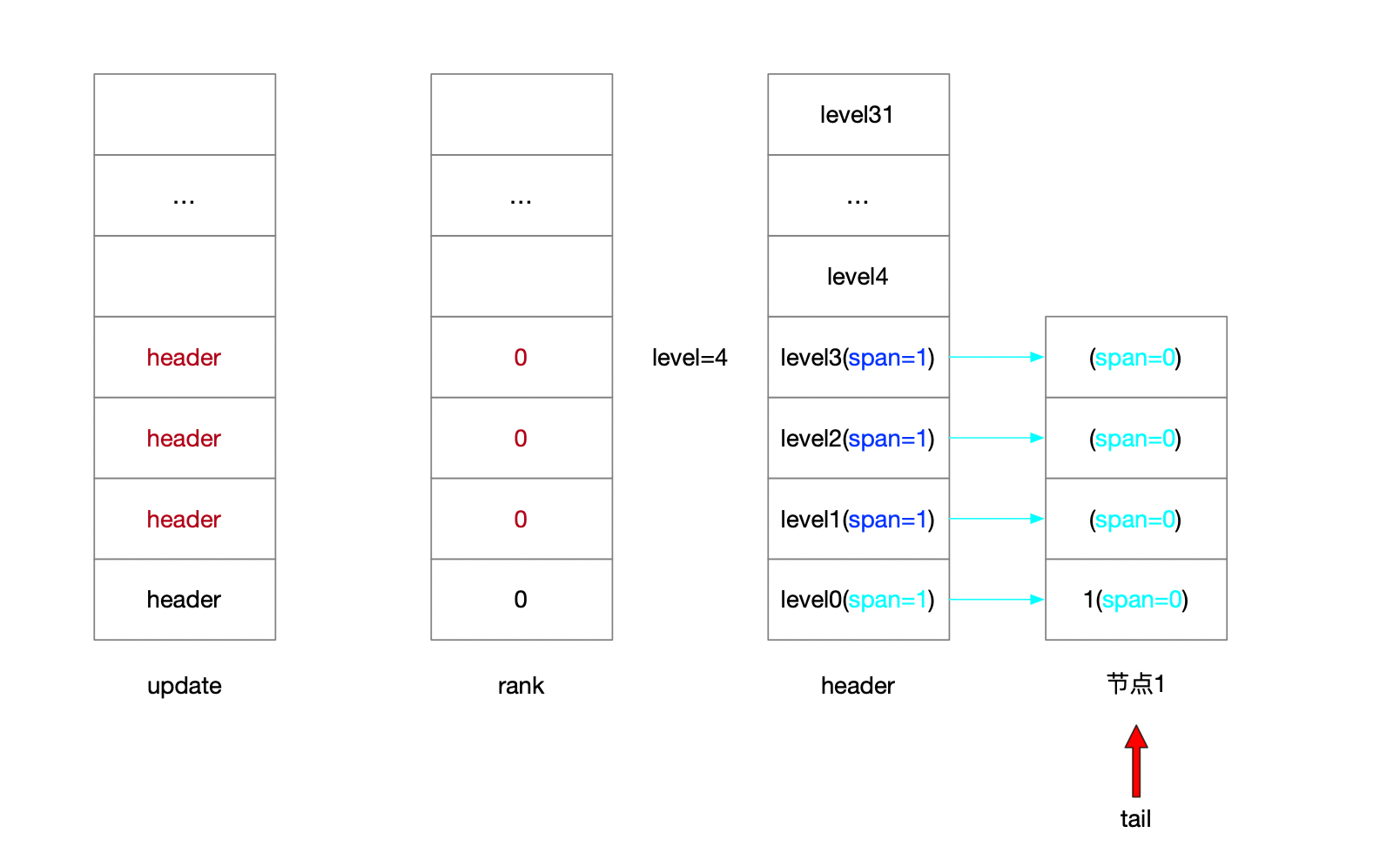
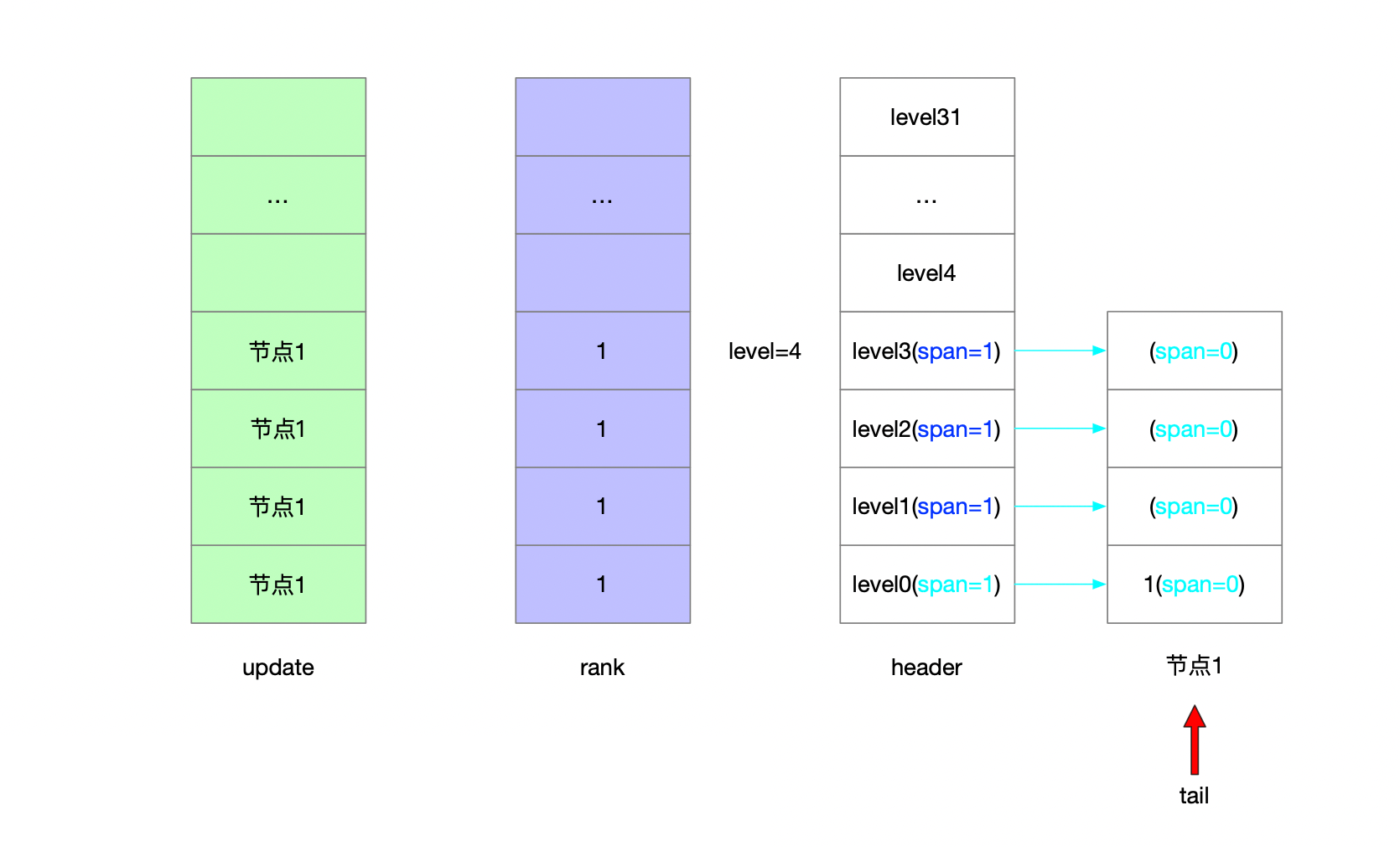
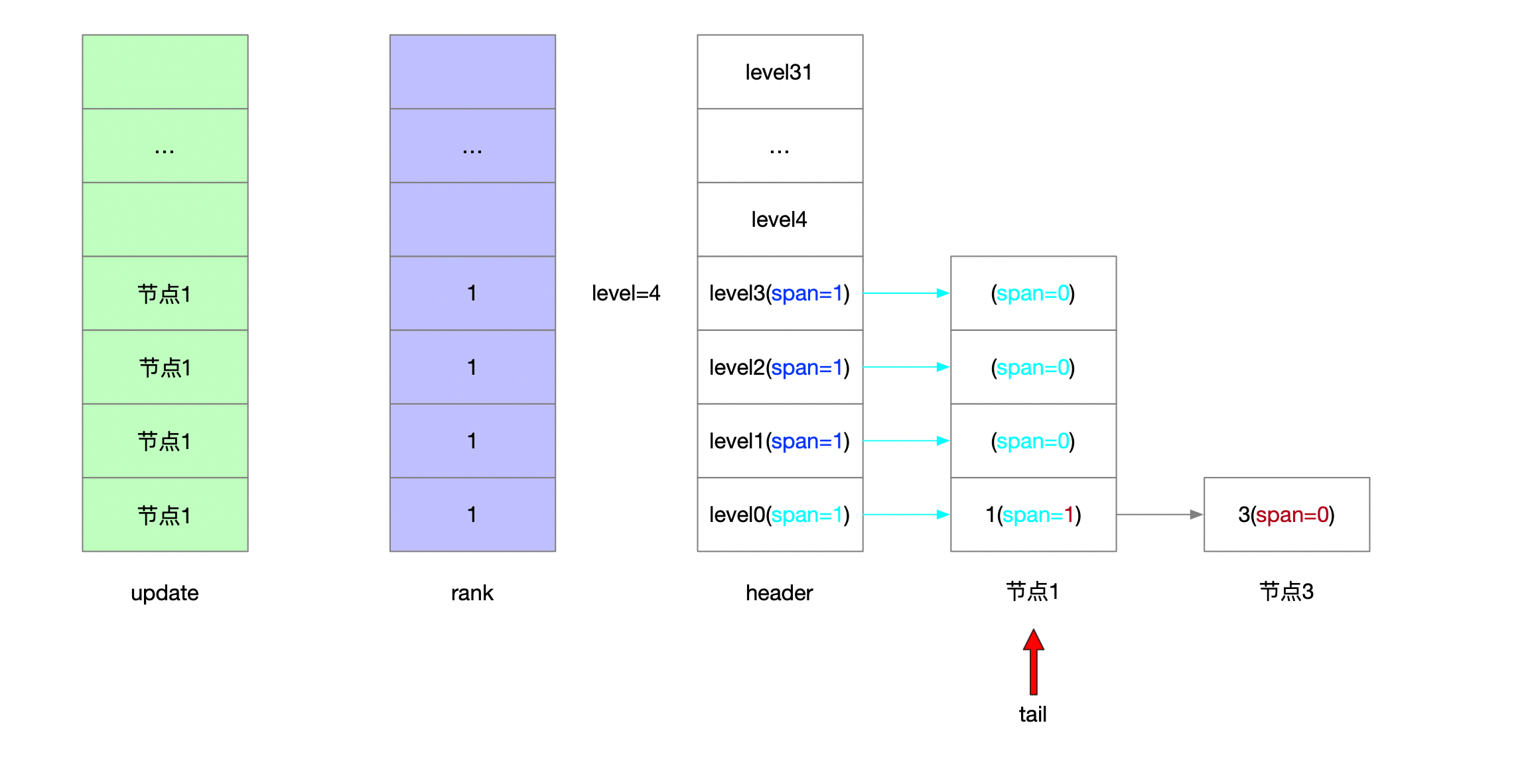
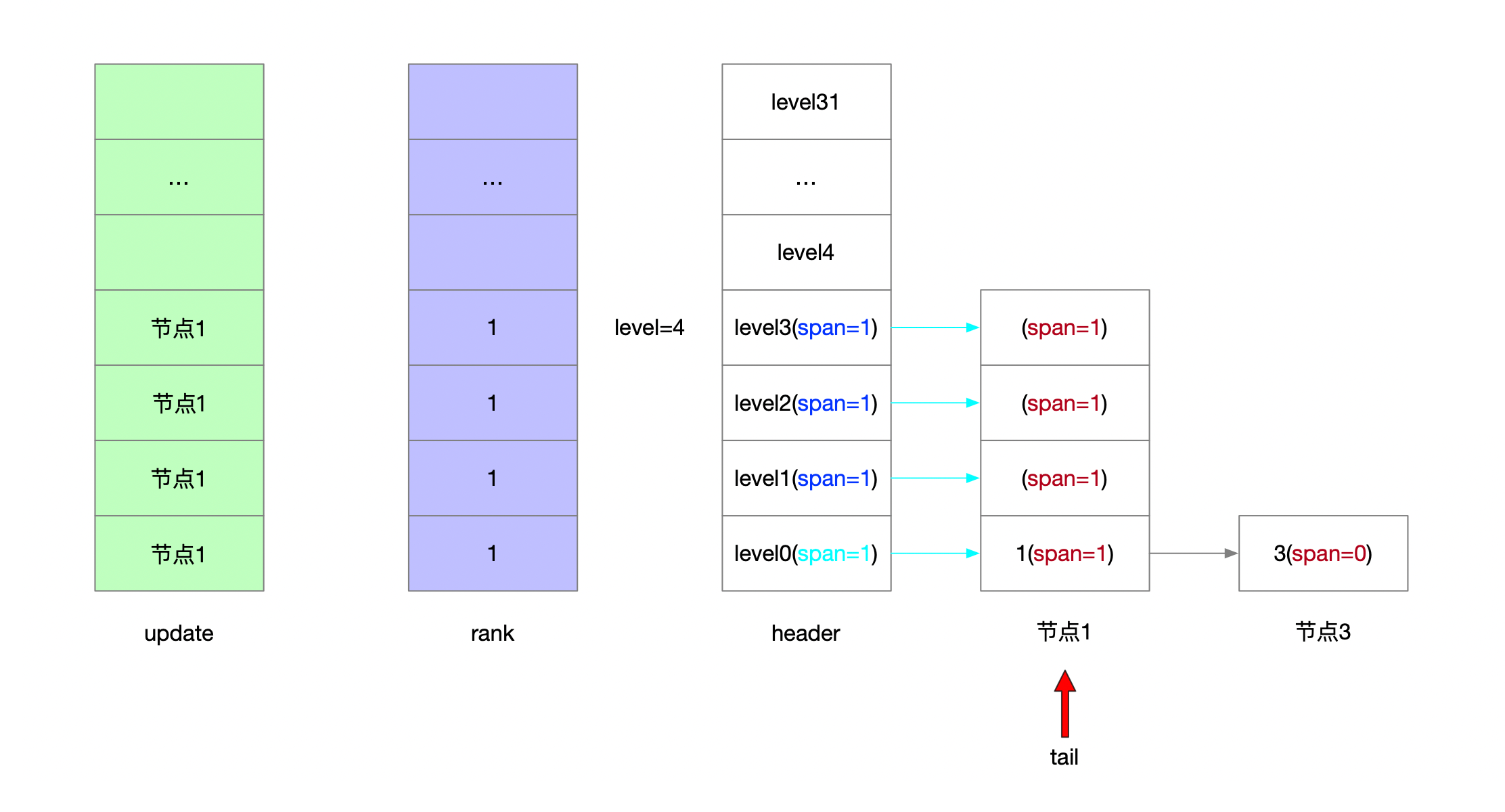
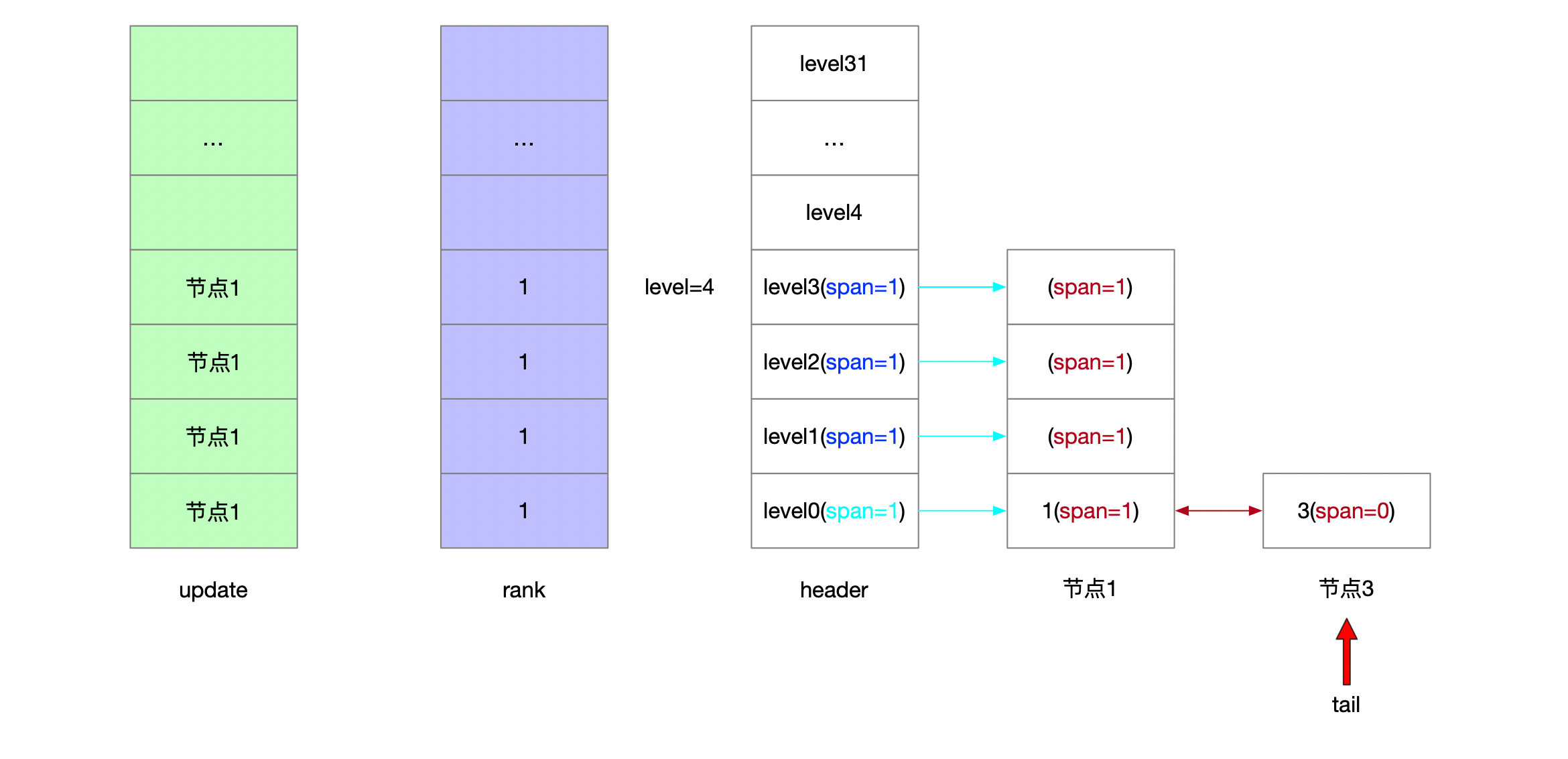
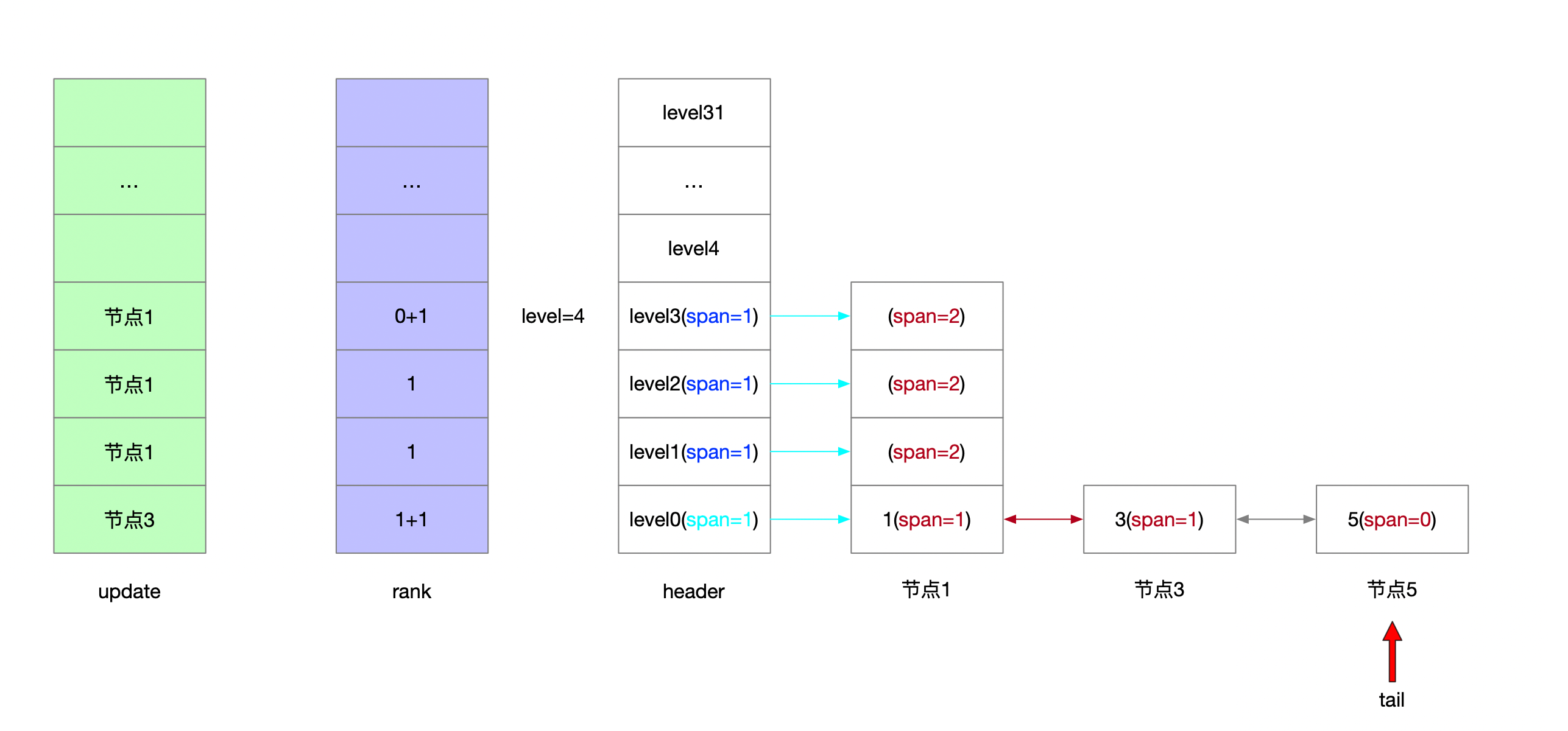
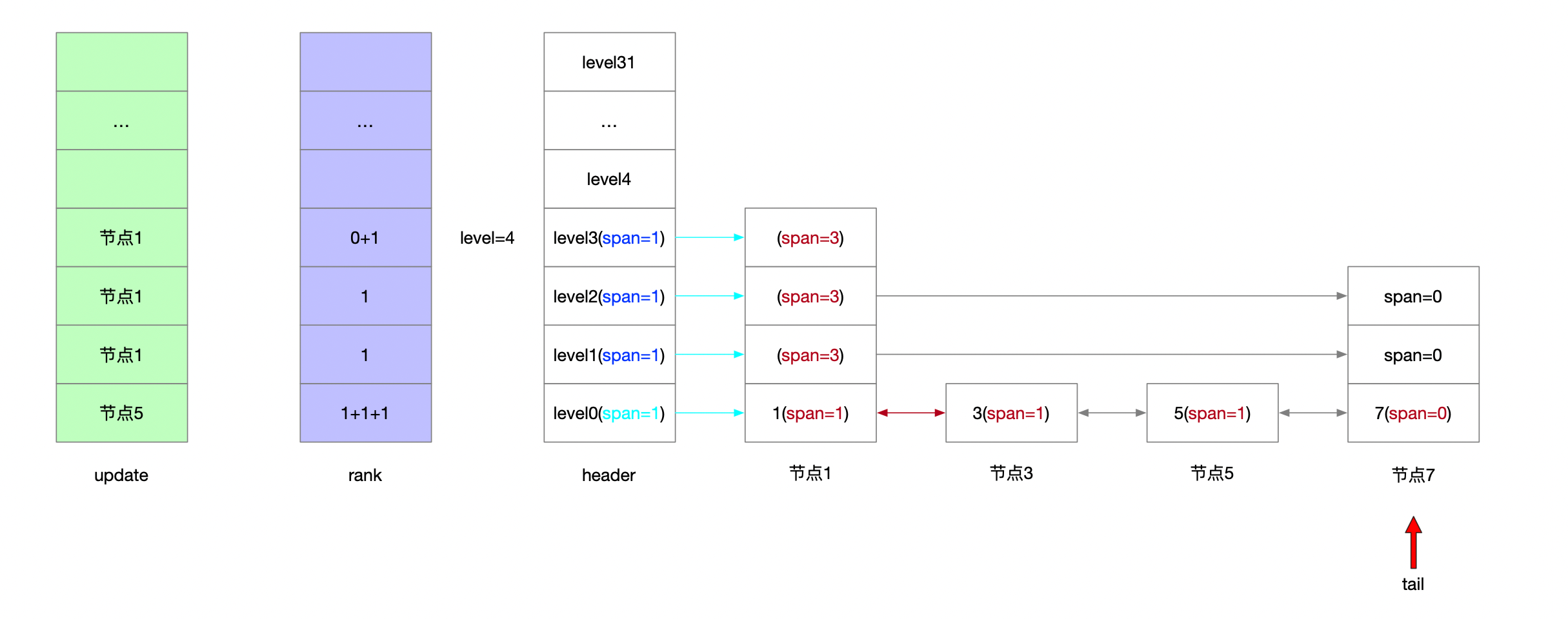
serverAssert(!isnan(score)); /** * 第一步: * * 跳表的理论层高区间是[1...32] * 跳表的实际层高区间是[1...level] * header上一定维护着[1...level]的层高 * * 从header头节点开始往tail节点遍历 查找当前要写入的元素的位置 * * [oldLevel...1]层高上从head节点->tail节点开始遍历 * 将搜索路径信息维护在update表和rank表中 */ x = zsl->header; for (i = zsl->level-1; i >= 0; i--) { /* store rank that is crossed to reach the insert position */ rank[i] = i == (zsl->level-1) ? 0 : rank[i+1]; while (x->level[i].forward && (x->level[i].forward->score < score || (x->level[i].forward->score == score && sdscmp(x->level[i].forward->ele,ele) < 0))) { rank[i] += x->level[i].span; x = x->level[i].forward; } update[i] = x; } /* we assume the element is not already inside, since we allow duplicated * scores, reinserting the same element should never happen since the * caller of zslInsert() should test in the hash table if the element is * already inside or not. */ /** * 第二步: * * [1...32]随机层高 随机出来的节点高度可能比跳表高度要高 因此补充update和rank表 * 层高区间为[newLevel...oldLevel] */ level = zslRandomLevel(); if (level > zsl->level) { for (i = zsl->level; i < level; i++) { rank[i] = 0; update[i] = zsl->header; update[i]->level[i].span = zsl->length; } zsl->level = level; } /** * 第三步: * * 新建的跳表节点 * 维护[1...newLevel]层高信息 * 按照update和rank表维护新节点所有层上的前进节点和步进信息 更新各层上update表节点的步进信息 */ x = zslCreateNode(level,score,ele); for (i = 0; i < level; i++) { /** * 新建节点的前进指针 * 新建节点的前驱节点的前进指针 */ x->level[i].forward = update[i]->level[i].forward; update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */ /** * 新建节点的步进值 * rank[0]就是插入节点的前驱节点 */ x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]); update[i]->level[i].span = (rank[0] - rank[i]) + 1; }
/* increment span for untouched levels */ /** * 第四步: * 可能随机出来的层高是比老跳表的层高要低的 那么新节点未涉及的层高也要更新步进信息 * 层高区间为[newLevel...oldLevel] */ for (i = level; i < zsl->level; i++) { update[i]->level[i].span++; }