/* Get the index of the new element, or -1 if * the element already exists. */ /** * index -1表示key在dict中hash表数组脚标计算不出来 * <ul> * <li>key已经存在了 把存在的key返回出去 dict不允许重复key 调用方就去更新value值就完成了add新键值对的语义</li> * <li>诸如扩容失败导致计算不出来key落在数组的位置</li> * </ul> */ if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1) returnNULL;
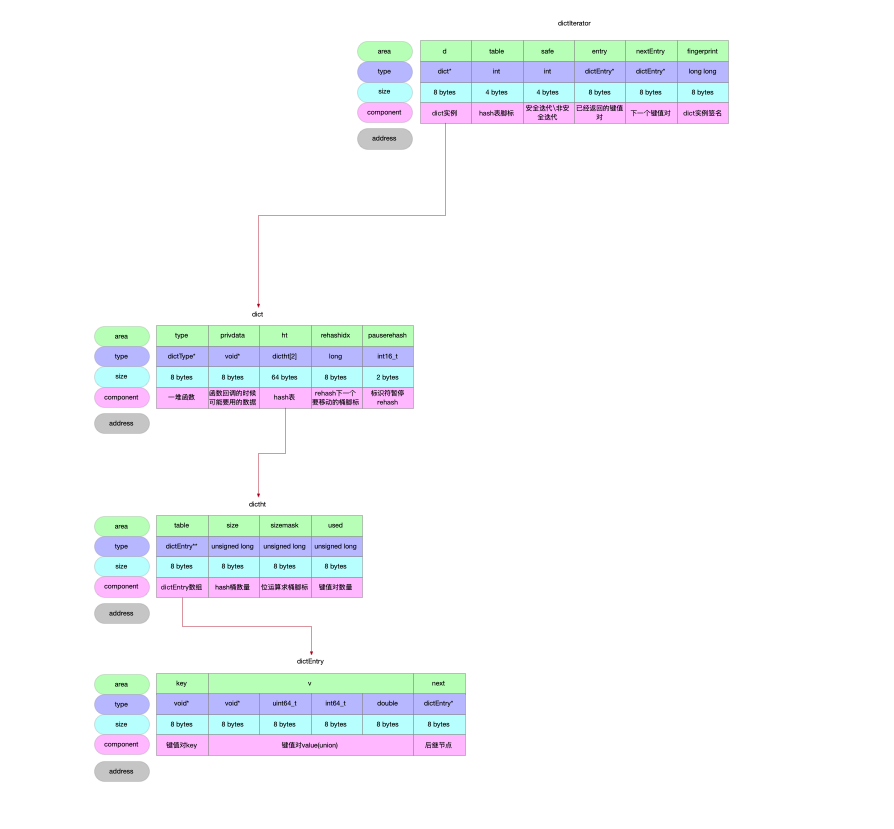
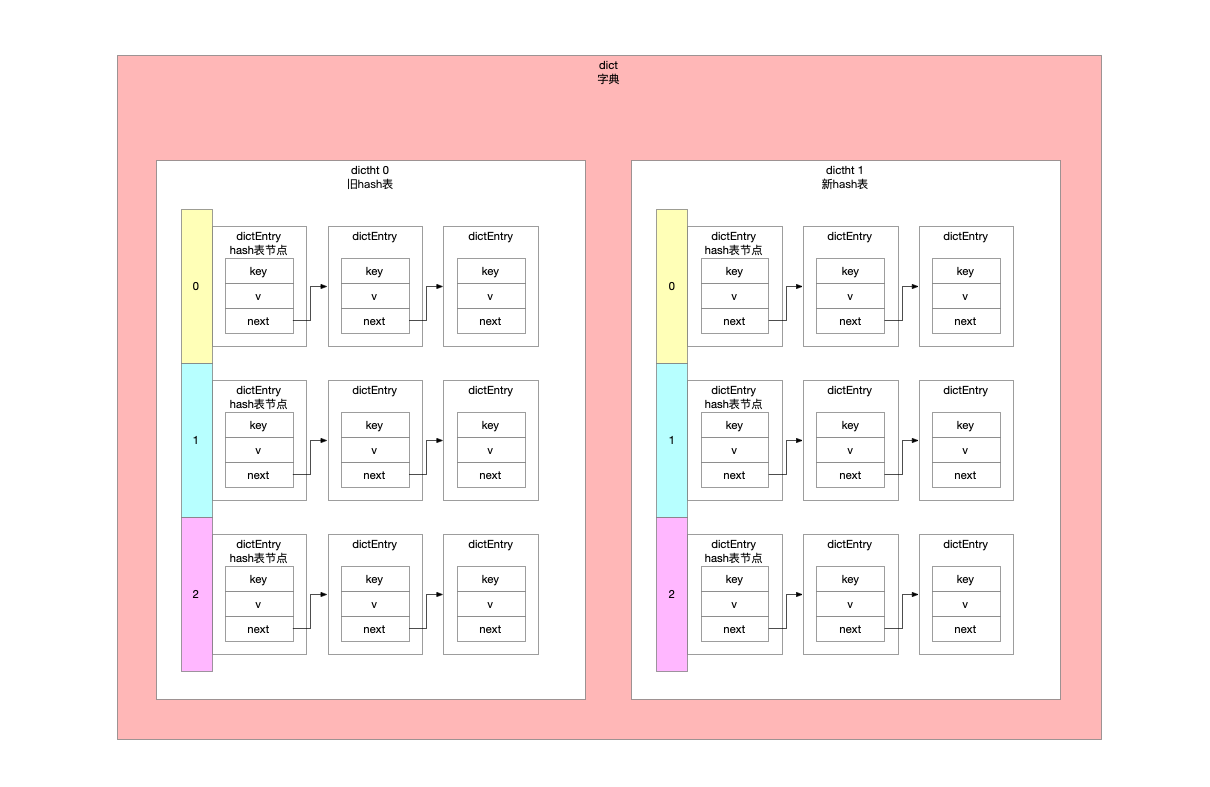
/* Allocate the memory and store the new entry. * Insert the element in top, with the assumption that in a database * system it is more likely that recently added entries are accessed * more frequently. */ /** * 数据往哪儿写 * <ul> * <li>dict可能只有1个hash表</li> * <li>可能有2个hash表</li> * </ul> * 取决于当前dict的状态 在rehash中就有2个表 * 既然在rehash 就是处在把[0]号表元素往[1]号表迁移的过程中 * 所以新增的数据就不要往[0]号表写了 然后再迁移 * 直接一步到位 写到[1]号表上去 */ ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0]; // 键值对 实例化 初始化 entry = zmalloc(sizeof(*entry)); // 经典的单链表头插法 entry->next = ht->table[index]; ht->table[index] = entry; // 键值对计数 ht->used++;
/* Set the hash entry fields. */ // 设置节点的key dictSetKey(d, entry, key); return entry; }
/* If the hash table is empty expand it to the initial size. */ // hash表刚初始化出来 把hash表数组初始化到4个长度 if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* If we reached the 1:1 ratio, and we are allowed to resize the hash * table (global setting) or we should avoid it but the ratio between * elements/buckets is over the "safe" threshold, we resize doubling * the number of buckets. */ /** * 扩容时机 * <ul> * <li>键值对的数量已经达到了hash表数组长度 就平均而言 可以理解为最坏情况下每个hash桶都被占了</li> * <li>并且每个hash桶里面的链表长度平均超过了5</li> * </ul> * 核心还是因为担心最坏情况下某个或者某些链表过长导致检索的时间复杂度过高 所以用空间换时间 */ // TODO: 2023/12/13 这个地方有2点没明白 在dictTypeExpandAllowed和当前这个函数中 为什么用used+1而不是直接用used 从上面的判断分支走下来 used为0的情况早已经排除了 if (d->ht[0].used >= d->ht[0].size && (dict_can_resize || d->ht[0].used/d->ht[0].size > dict_force_resize_ratio) && dictTypeExpandAllowed(d)) { // 扩容新的数组长度是>节点数的2的幂次方 也就为扩容基准并不是现在数组大小 而是现在节点数量 最坏情况下没有hash冲突保证容纳所有节点 return dictExpand(d, d->ht[0].used + 1); } return DICT_OK; }
/* Rehashing to the same table size is not useful. */ // 依然是校验 if (realsize == d->ht[0].size) return DICT_ERR;
/* Allocate the new hash table and initialize all pointers to NULL */ // 初始化hash表成员 n.size = realsize; n.sizemask = realsize-1; // 根据实参设定 决定处理OOM的时机 if (malloc_failed) { // 太try了 n.table = ztrycalloc(realsize*sizeof(dictEntry*)); *malloc_failed = n.table == NULL; if (*malloc_failed) return DICT_ERR; } else n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing * we just set the first hash table so that it can accept keys. */ /** * 扩容的函数暴露给了外面 那么触发扩容的时机就起码有2处 * <ul> * <li>dict实例化之后还没put数据 就手动主动进行expand</li> * <li>dict在put过程中触发了数组长度使用阈值 被动触发扩容</li> * </ul> * dict刚实例化完 直接把新表给[0]号就行 */ if (d->ht[0].table == NULL) { d->ht[0] = n; return DICT_OK; }
/* Prepare a second hash table for incremental rehashing */ /** * 因为hash表数组长度使用触发了扩容阈值 * 新表给到[1]号表 * 标记rehash标识 */ d->ht[1] = n; d->rehashidx = 0; return DICT_OK; }
/* Note that rehashidx can't overflow as we are sure there are more * elements because ht[0].used != 0 */ /** * 防止数组脚标溢出 * rehashidx是标识的要迁移的hash桶 也就是数组脚标指向的数组元素 将来要通过arr[rehashidx]方式来获取数组元素的 防止溢出 */ assert(d->ht[0].size > (unsignedlong)d->rehashidx); /** * <ul> * <li>一方面 跳过hash表数组中的空桶</li> * <li>另一方面 统计总共遍历了多少个桶 考察是不是达到了遍历上限</li> * </ul> */ while(d->ht[0].table[d->rehashidx] == NULL) { d->rehashidx++; if (--empty_visits == 0) return1; } /** * 不是空桶 * 准备把整条单链表迁移走 轮询单链表所有节点 依次迁移走 */ de = d->ht[0].table[d->rehashidx]; /* Move all the keys in this bucket from the old to the new hash HT */ // de指向hash桶的链表头 遍历链表将节点逐个迁移到新表上 while(de) { uint64_t h;
nextde = de->next; /* Get the index in the new hash table */ // key在新表的hash桶位置 h = dictHashKey(d, de->key) & d->ht[1].sizemask; // hash表长度是2的幂次方 通过位运算计算key的hash桶脚标 // 单链表头插法 de->next = d->ht[1].table[h]; d->ht[1].table[h] = de; d->ht[0].used--; // 旧表上每迁移走一个键值对 就更新计数 d->ht[1].used++; // 新表上每迁过来一个键值对 就更新计数 de = nextde; } d->ht[0].table[d->rehashidx] = NULL; // 一个桶上单链表所有节点都迁移完了 d->rehashidx++; // 一个桶迁移结束后 下一次迁移的脚标位置 }
/* Check if we already rehashed the whole table... */ // rehash任务完成后判定一下hash表是否都迁移完成了 // 迁移完成了就回收老表 把表1指向新表 if (d->ht[0].used == 0) { zfree(d->ht[0].table); d->ht[0] = d->ht[1]; _dictReset(&d->ht[1]); d->rehashidx = -1; return0; }