Redis-0x0f-zskiplist
数据类型的编码方式。
1 数据结构
1.1 跳表节点
c
1 | |
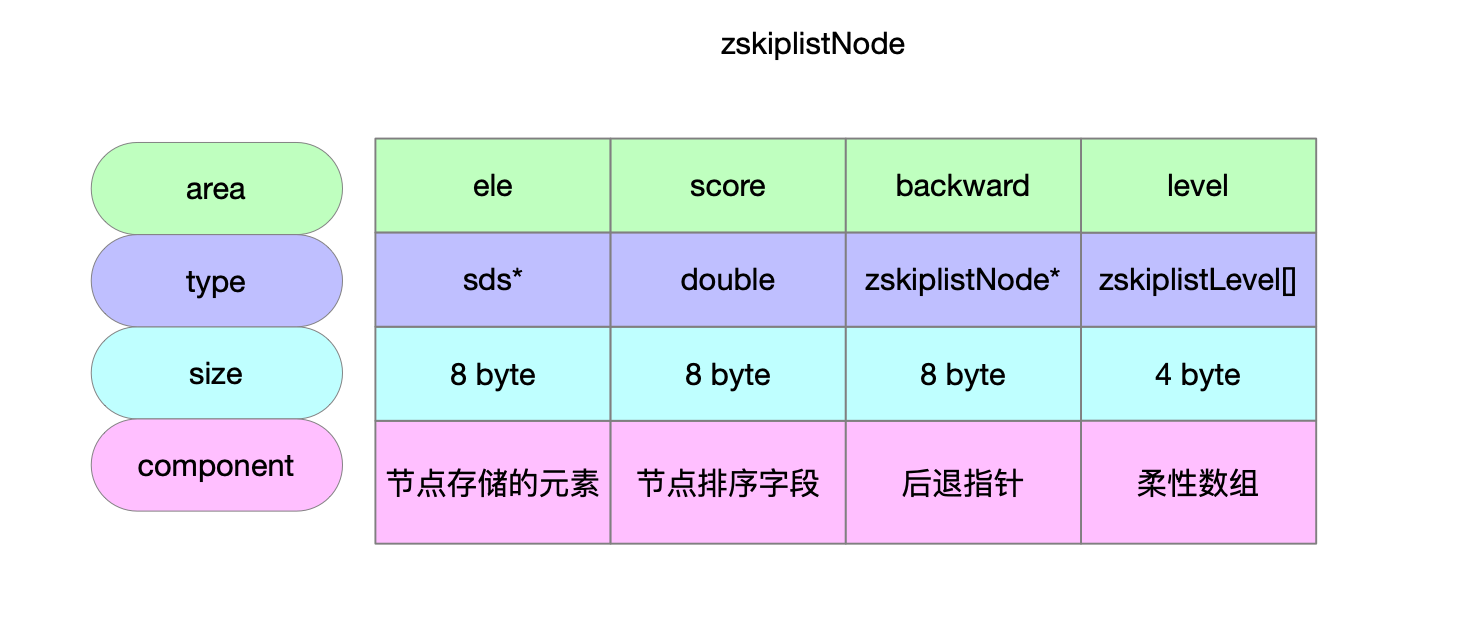
1.2 跳表
c
1 | |
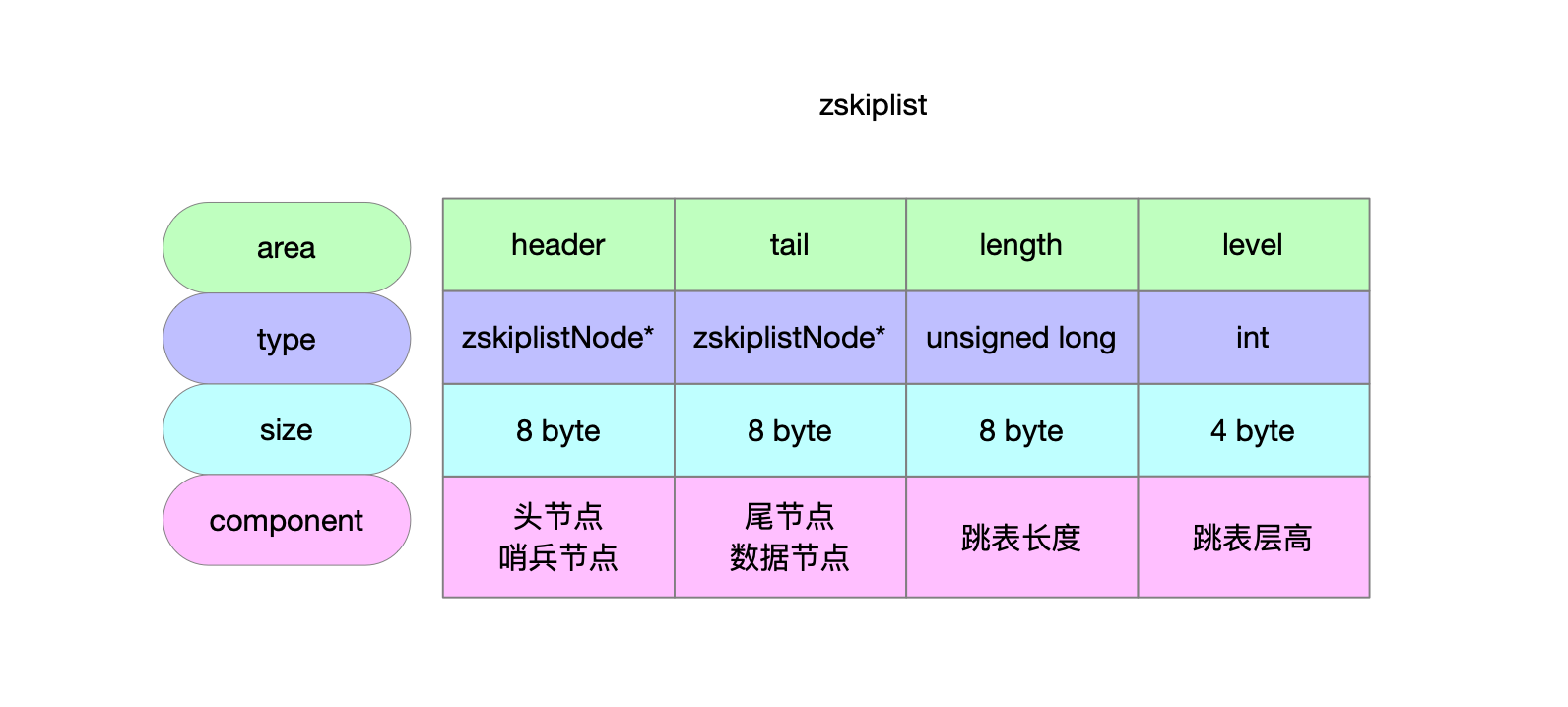
2 创建跳表节点
c
1 | |
3 创建跳表
c
1 | |
初始化完成的跳表只有一个header节点。

4 增
4.1 插入元素
4.1.1 向跳表插入新元素
c
1 | |
4.1.2 图解
4.1.2.1 空跳表
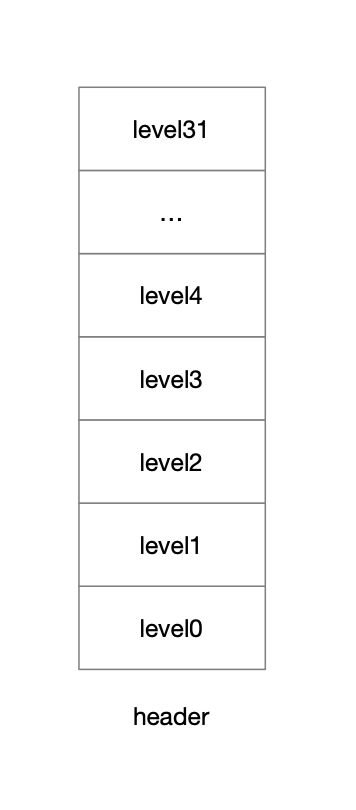
4.1.2.2 插入1 随机层高4
4.1.2.2.1 update和rank维护检索路径
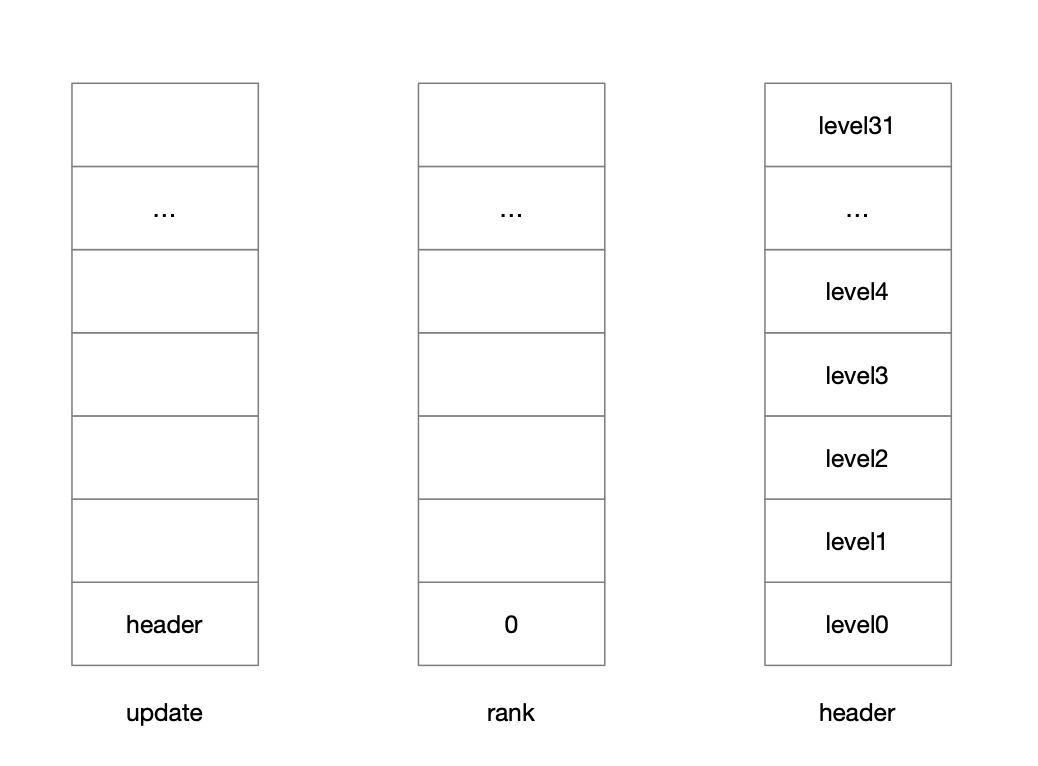
4.1.2.2.2 随机层高为4并补充update和rank

4.1.2.2.3 新建节点维护各层连接信息
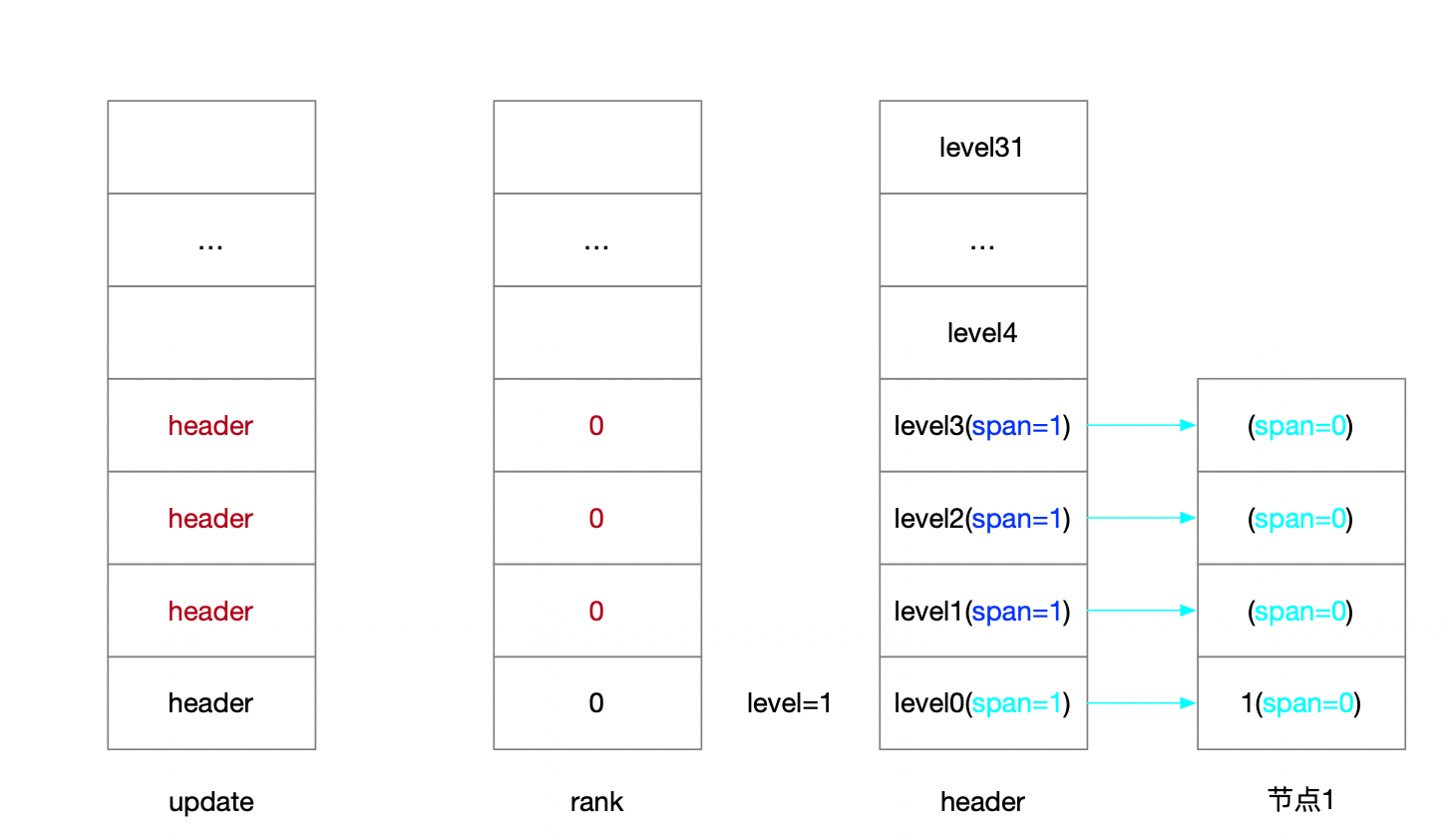
4.1.2.2.4 维护后退指针
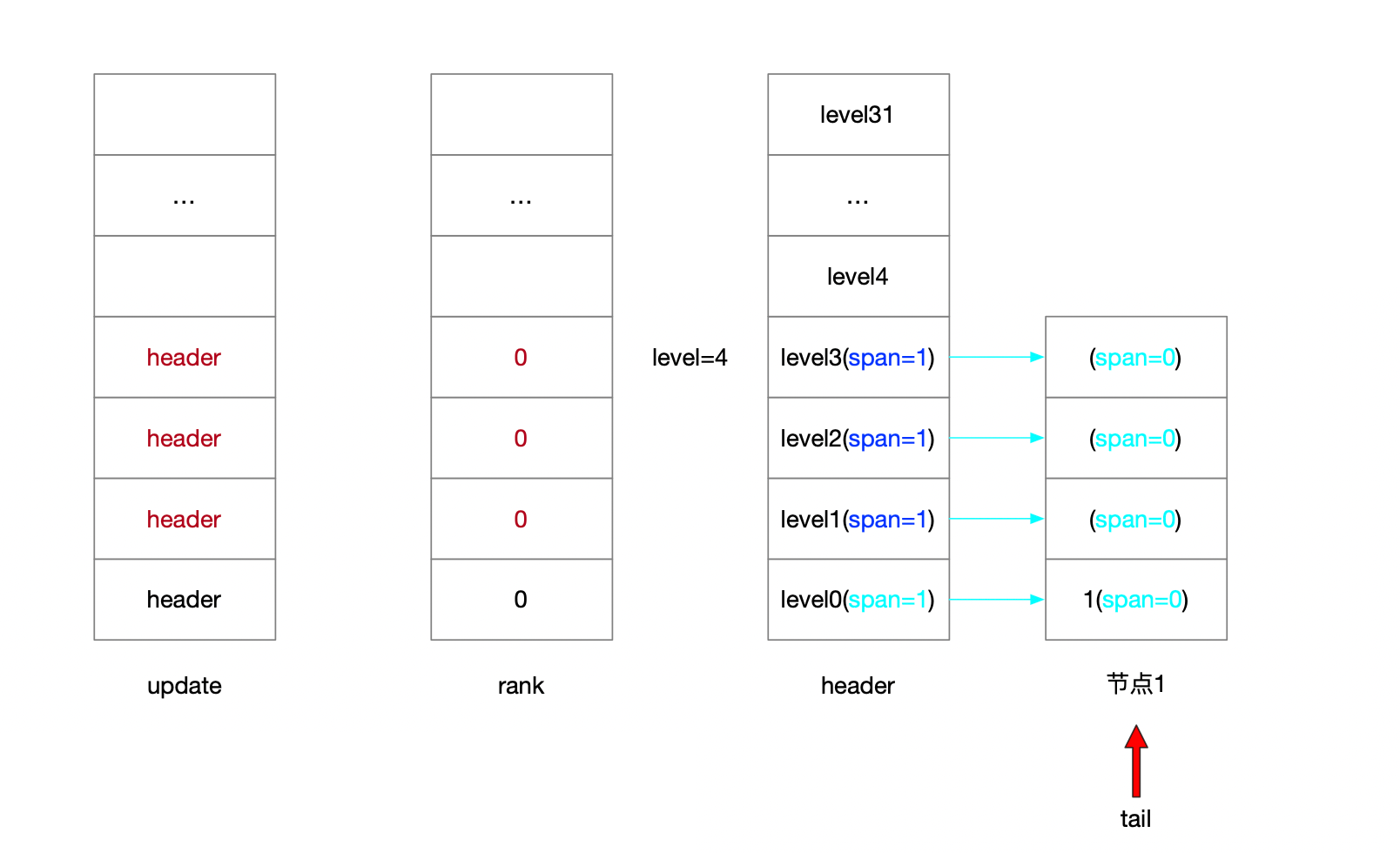
4.1.2.3 插入3 随机层高1
4.1.2.3.1 维护update和rank
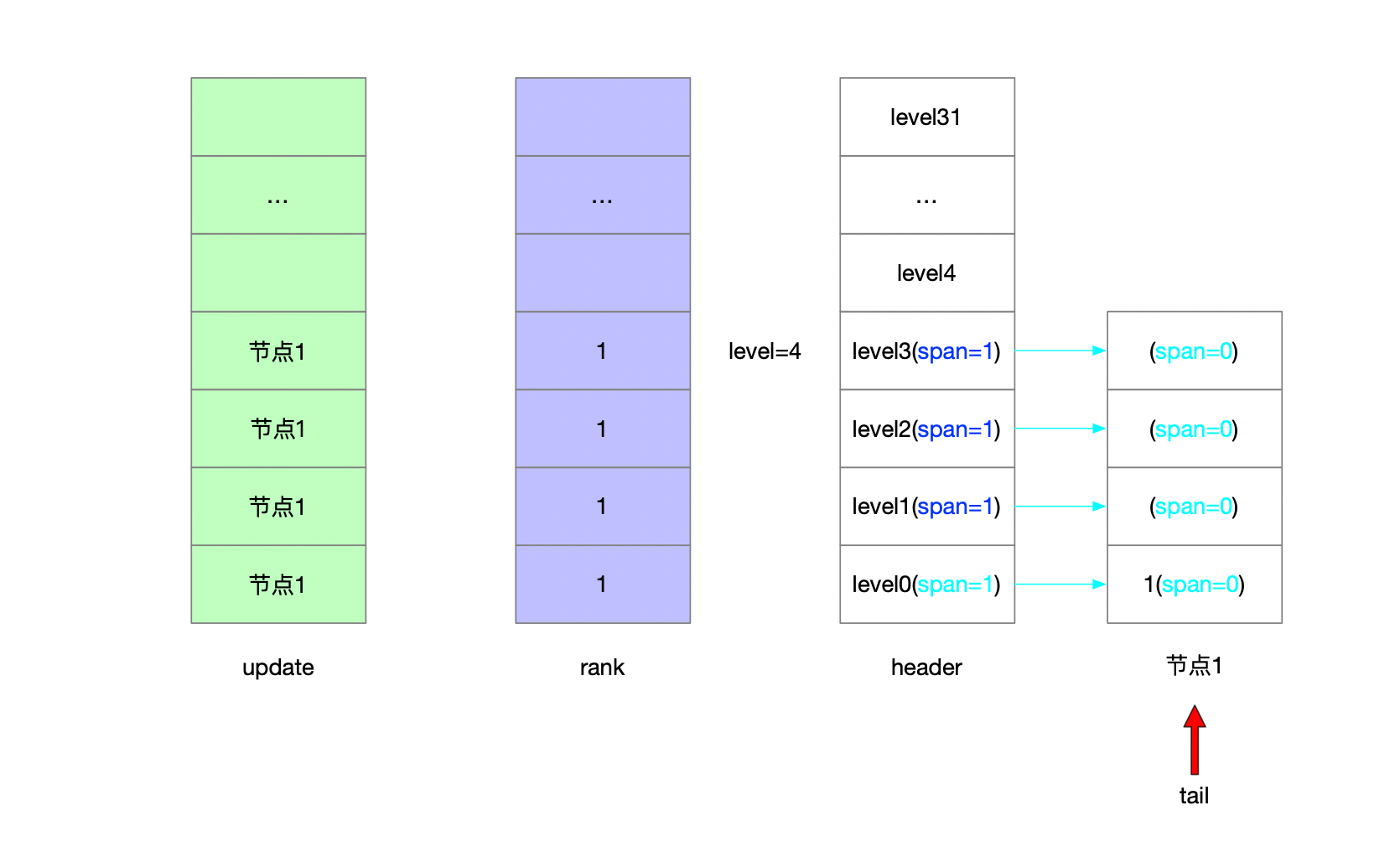
4.1.2.3.2 前进指针和步进值
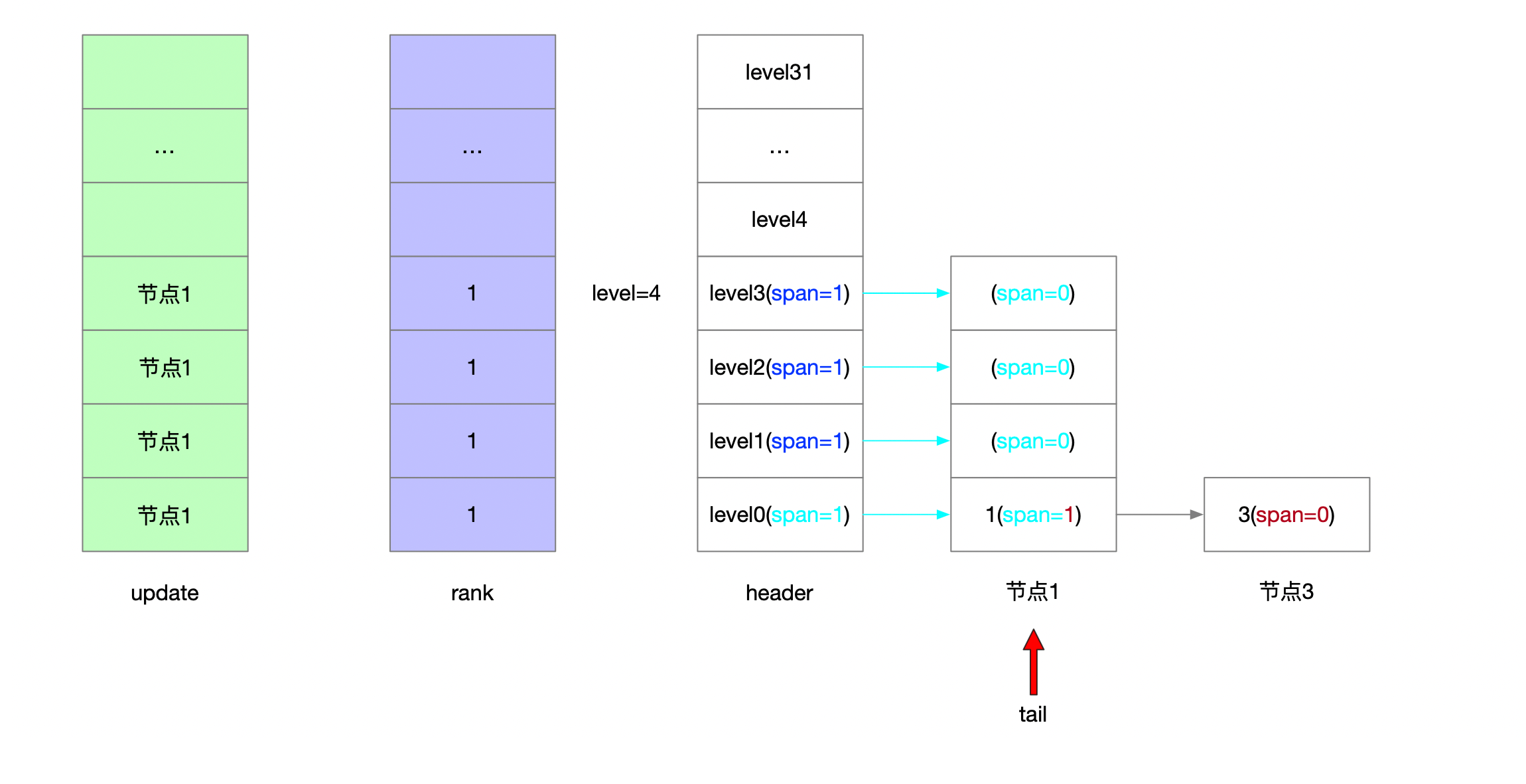
4.1.2.3.3 新节点未涉及层高步进值
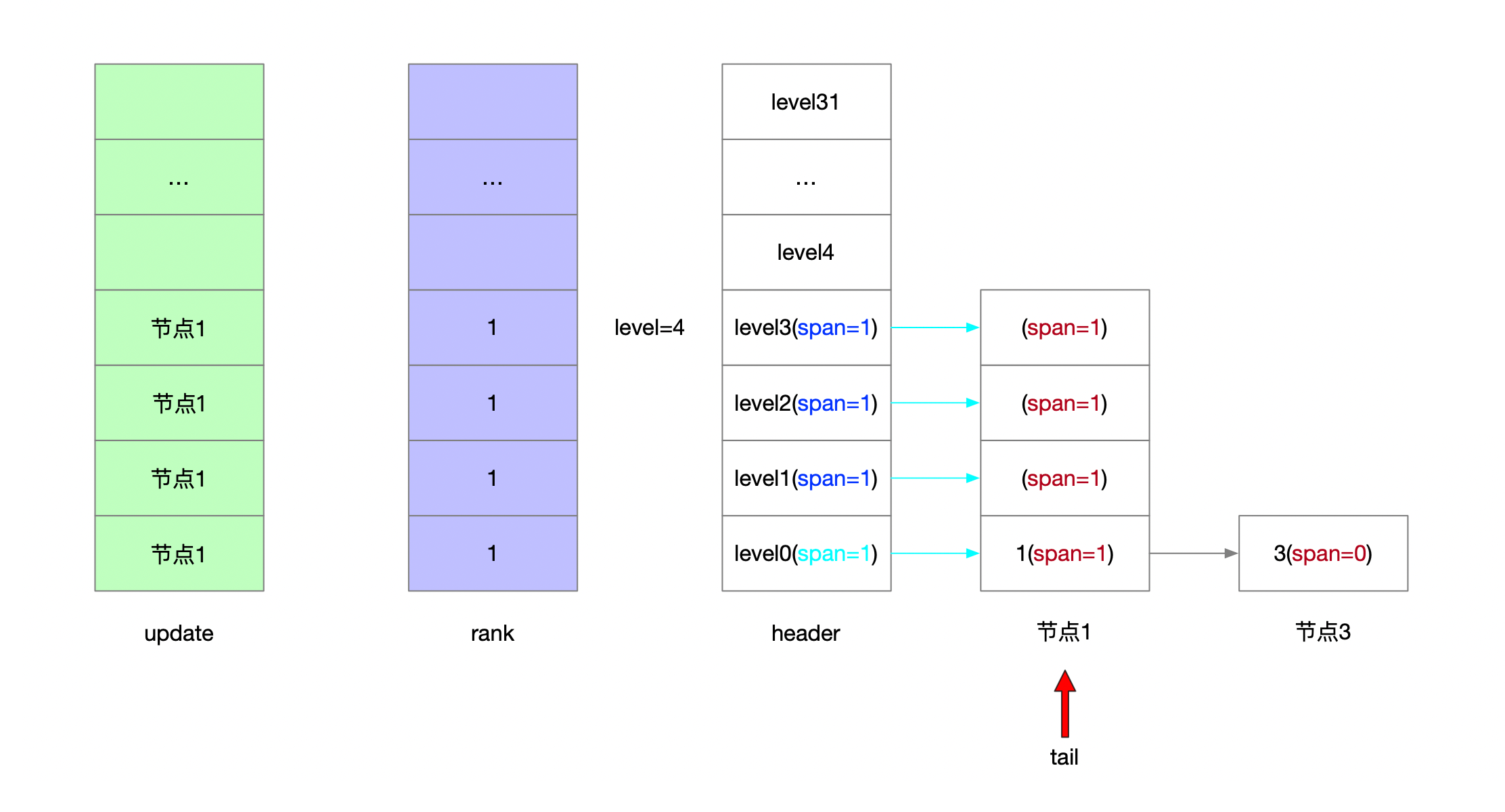
4.1.2.3.4 后退指针
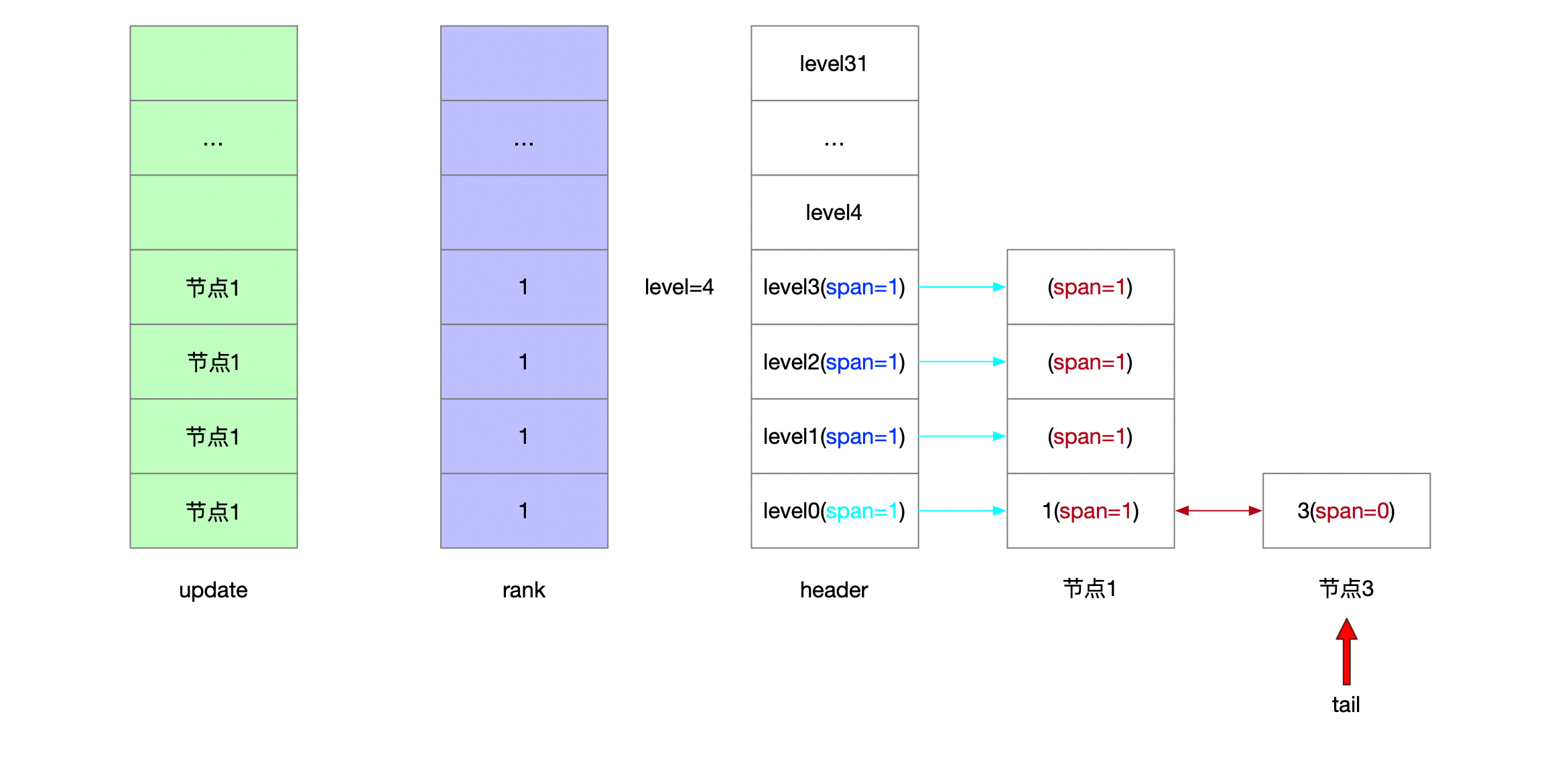
4.1.2.4 插入5 随机层高1
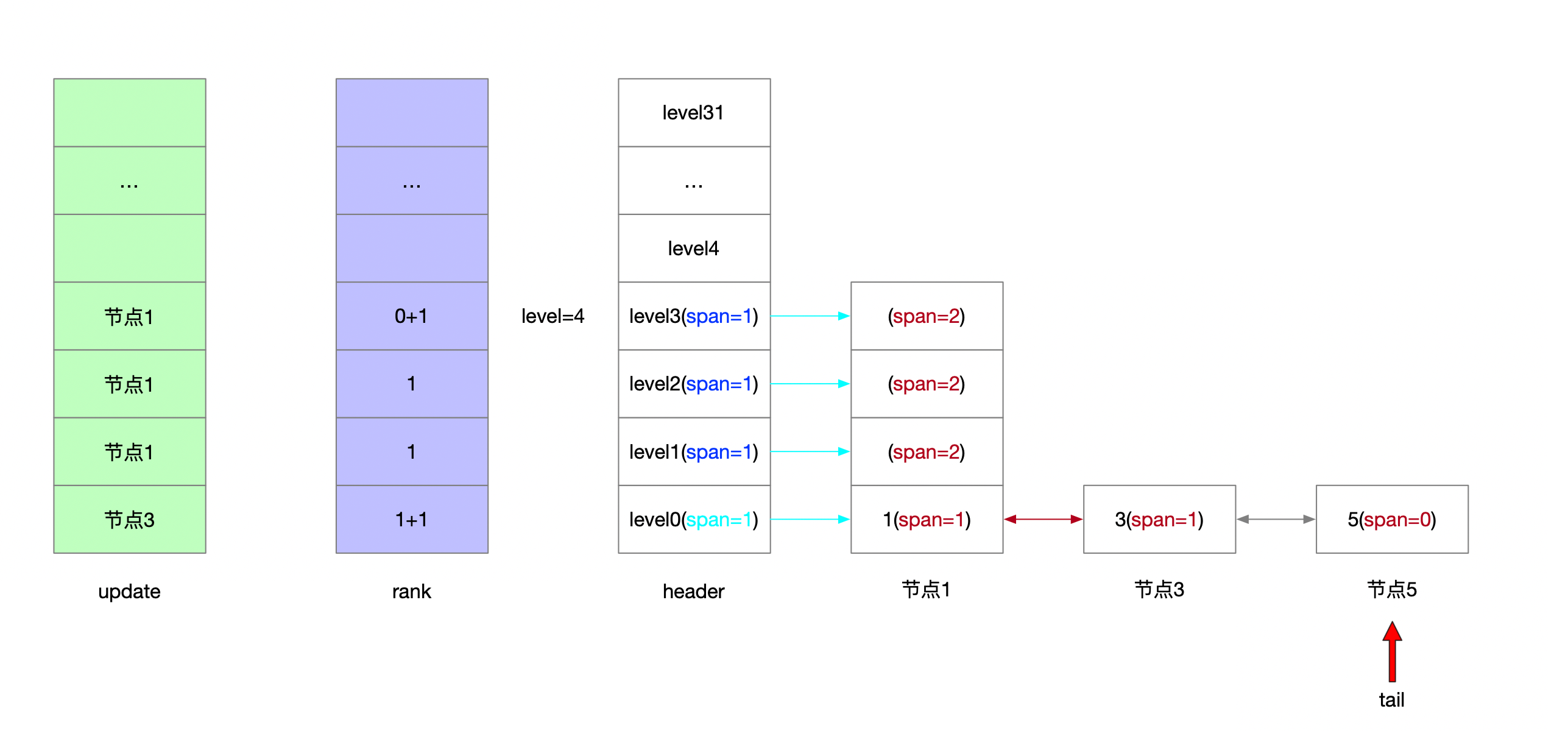
4.1.2.5 插入7 随机层高3
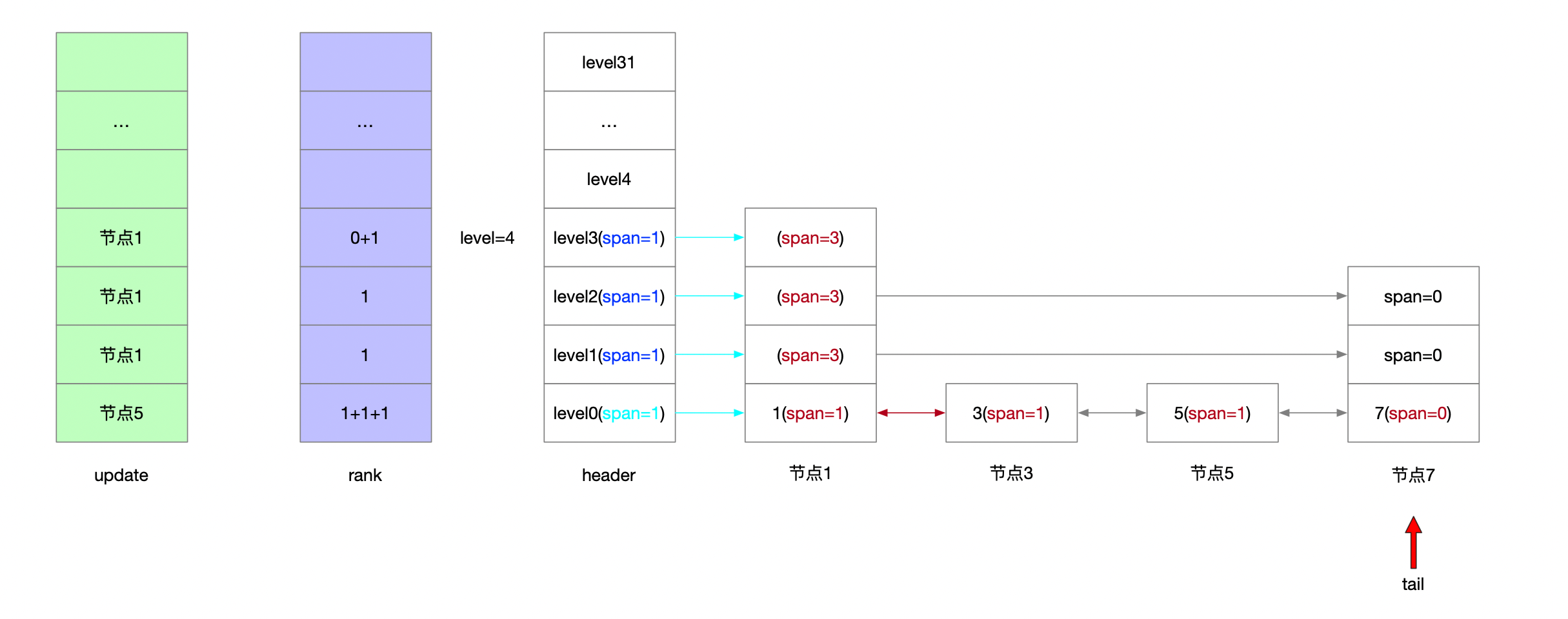
4.2 节点随机层高
c
1 | |
5 删
6 改
7 查
Redis-0x0f-zskiplist
https://bannirui.github.io/2023/04/06/Redis-0x0f-zskiplist/