ZK@3.8源码-13-选主过程通信和算法
我们一贯的套路是先总览框架,然后细看每个组件,最后再梳理整个流程。
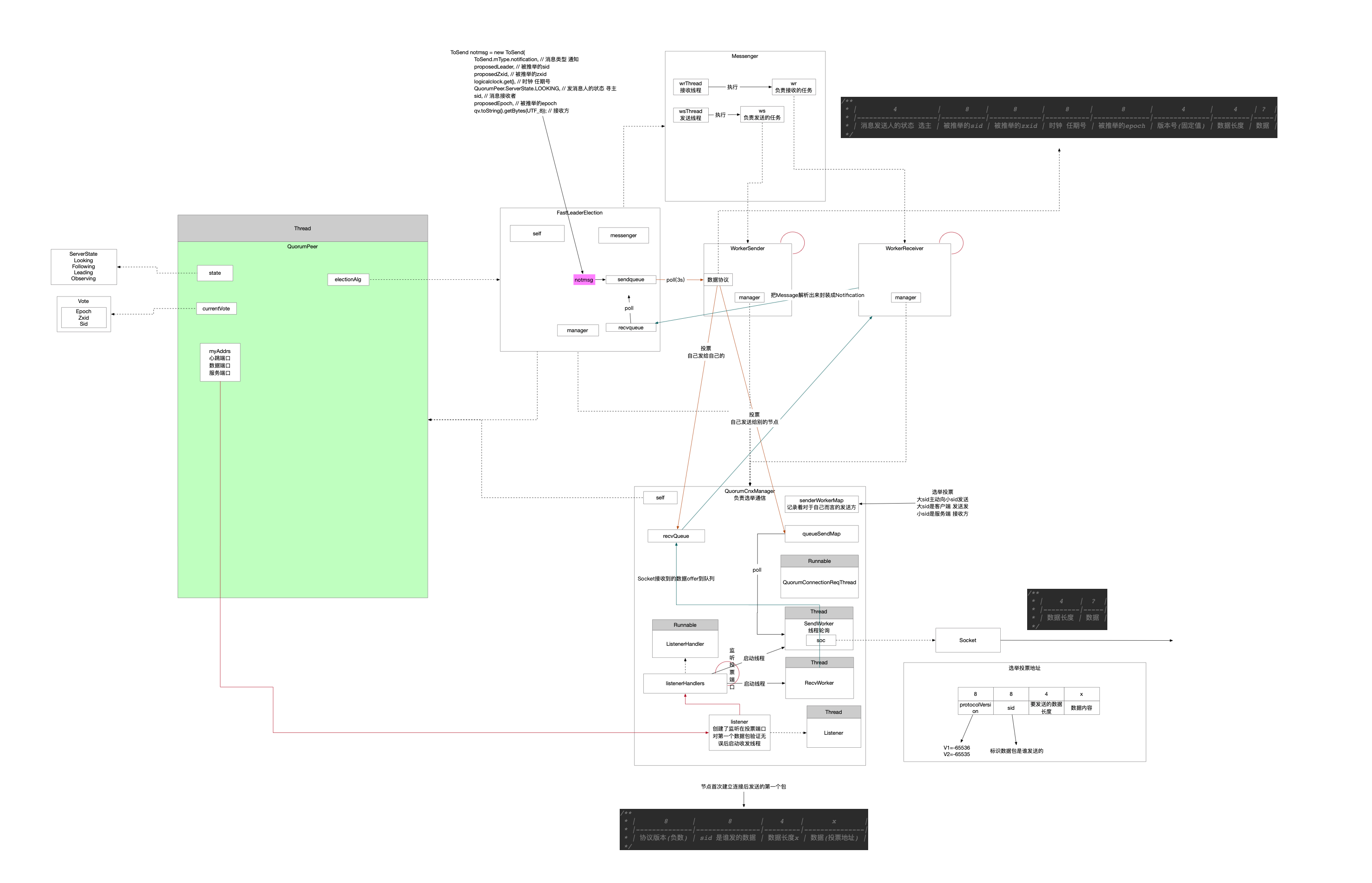
1 组件图
在选主算法中,涉及到的组件有:
- QuorumPeer 负责入口的驱动
- QuorumCnxManager 负责网络通信 对接的数据协议是字节和Message
- ListenerHandler 负责通信连接和验证
- RecvWorker 负责网络数据接收的线程
- SenderWorker 负责网络数据发送的线程
- FastLeaderElection 选主算法实现
- Messenger 负责承接通信的数据和算法主体 对接的数据协议是Message和Notification
- WorkerReceiver 负责将QCM收的Message转换成Notification给FLE
- WorkerSender 负责将QCM创建的投票Notification转换成Message发送
- 算法本体
- 负责选主实现
- Messenger 负责承接通信的数据和算法主体 对接的数据协议是Message和Notification
现在虽然每个组件功能已经分析过,但是比较孤立,不知道组件之间如何协调工作,下面我将以数据驱动的方式梳理全流程。
2 流程图
整个选主流程可以分为两块:
- 通信 这个通信是泛指
- 可以是跨机器的网络通信
- 也可以是伪集群方式的本机跨进程
- 投票算法
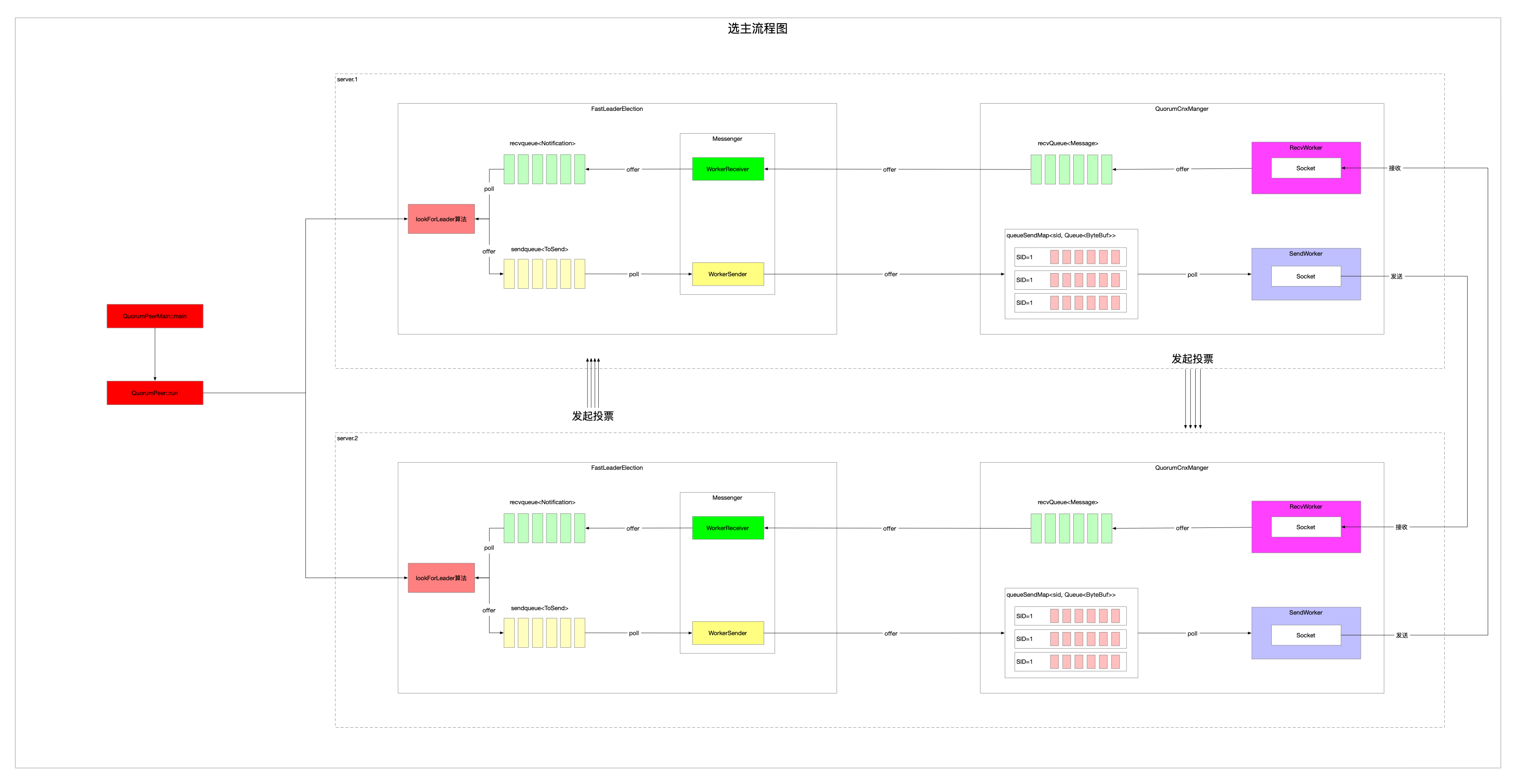
3 一个例子驱动流程
为了兼顾下面两块内容,参与的节点越少网络模块越简单,所以假设配置ZK集群模式,共配置了两个节点,没有Observer。
配置如下:
1 | |
约定:
- 先启动1
- 再启动2
3.1 网络通信
3.1.1 server1监听投票端口
时机发生在QuorumCnxManager::Listener::ListenerHandler::run()
创建QCM组件的时候会触发投票端口的监听,现在没有线程阻塞在accept上,等待别人连接。
1 | |
3.1.2 server1启动Messenger中两个线程
时机发生在QuorumPeer::createAlgoritm()
1 | |
启动两个线程
- wrThread
- wsThread
线程被CPU调度起来之后回调线程里面的任务,任务本质是两个任务线程
- WorkerReceiver
- WorkerSender
此刻这两个任务线程都在空轮询着。
3.1.3 server1启动FLE选举算法寻主流程
启动时机发生在QuorumPeer::run()
1 | |
此刻FLE算法会先给自己投上一票,FLE把这一票放到sendqueue中。
3.1.4 server1发起对投票端口的连接
时机在FlastLeaderElection::Messenger::WorkerSender::run()
1 | |
上面WorkerSender线程一直监听在sendqueue队列上,发现有数据了,WorkerSender把数据从发送队列取出来
准备向集群中参与选主的节点都发送一下
- server1给自己发送信息直接放到FLE的recvqueue中
- server1发给server2节点的准备走网络,WorkerSender把消息放到QCM的queueSendMap中
- WorkerSender尝试从senderWorkerMap中取SenderWorker,让它来负责Socket发送
此刻,WorkerSender发现还没有server1跟server2的Socket连接,就触发Socket向ServerSocket的主动连接。
BTW,投票协议如下:
1 | |
时机在QuorumCnxManager::toSend()
1 | |
但是现在并没有server2还没启动,因此会一直报错server1跟server2没有Socket连接。
3.1.5 server2监听投票端口
这时候上面3.1.4的server1就可以向server2在通信端口上发起连接了。
并且一旦server2 accept了server1的连接之后他们就可以通信了,server1向server2发送的第一个数据包如下:
1 | |
这样的一个约定格式主要是为了验证彼此双方接下来都是只用这个端口通信投票内容,而不是其他无关内容。
比如有别的机器误连了server2投票端口,或者恶意攻击,server2都可以通过如上协议的数据确认对方身份,不符合验证的直接就关闭Socket了。
3.1.6 server2接收server1连接后的第一个包
时机在QuorumCnxManager::Listener::ListenerHandler::run()
1 | |
3.1.6.1 读取到了server1发来的验证数据包之后需要先做一下验证
1 | |
3.1.6.2 Socket连接建立方向不对
时机在QuorumCnxManager::handleConnection()
只能大sid主动向小sid发起连接请求,方向不对的先关闭连接然后如同3.1.4一样正确方向发起连接建立并发送验证包。
此刻上面3.1.4环节中server1向server2发过来的验证包,那条Socket连接已经被关闭了。
并且于此同时,server1会按照下面3.1.6.3环节收到server2向server1发送的连接验证包。然后server1通过了对连接验证包的验证,并且把server1在通信端口收到的Socket缓存起来了,以后server1和server2就用这条连接发送投票。
现在3.1.4中server1的那个投票信息就通过连接发给了server2。
1 | |
3.1.6.3 连接合法的就把Socket缓存在QCM的SenderWorker和RecvWorker里面,用于投票通信
时机在QuorumCnxManager::handleConnection()
1 | |
3.1.7 server2收到了server1的投票
RecvWorker将Socket上收到的投票放到recvQueue中
时机在QuorunCnxManager::RecvWorker::run()
1 | |
3.1.8 server2的WorkerReceiver轮询监听recvQueue中投票
时机FastLeaderElection::Messenger::WorkerReceiver::run()
1 | |
3.1.9 server2的WorkerReceiver将经过验证有效的投票投递给recvqueue
时机FastLeaderElection::Messenger::WorkerReceiver::run()
1 | |
3.1.10 server2的FLE算法工作
时机FastLeaderElection::lookForLeader()
1 | |
到此为止,选主过程中网络流向已经基本结束了,上面是从server1到server2方向的,反向的从server2到server1的通信也是一样的。
3.2 投票算法
为什么没有把投票算法原理也放在上面3.1,我觉得按照单独讲解算法原理比较清晰。
还是沿用上面3.1的例子,这个地方我就不贴源码了,源码看上一章节。
约定一下:
FLE proposed是每次FLE收到投票后都会根据PK进行更新
- PK参与方一是投票
- PK参与方二是proposed
revset是展示最新投票的投票箱
getVoteTracker是汇总投票计数
投票我们这样记x-[j,k,l]:
- x表示谁发起的投票
- j表示被推举的leader的epoch
- k表示被推举的leader的zxid
- l表示被推举的leader的sid
3.2.1 server1启动
server1投[0,1,0]
| server1 | server2 | |
|---|---|---|
| FLE proposed | [0,1,0] | |
| recvset | 1-[0,1,0] | |
| getVoteTracker | [0,1,0] 1票 |
3.2.2 server2启动
server2投[0,2,0]
| server1 | server2 | |
|---|---|---|
| FLE proposed | [0,2,0] | [0,2,0] |
| recvset | 1-[0,1,0] 2-[0,2,0] |
2-[0,2,0] |
| getVoteTracker | [0,1,0] 1票 [0,2,0] 1票 |
[0,2,0] 1票 |
3.2.2 server1改票
server1投[0,2,0]
| server1 | server2 | |
|---|---|---|
| FLE proposed | [0,2,0] | [0,2,0] |
| recvset | 2-[0,2,0] 1-[0,2,0] |
2-[0,2,0] 1-[0,2,0] |
| getVoteTracker | [0,2,0] 2票 | [0,2,0] 2票 |
至此[0,2,0]当选leader获选2票,过半了,被推举为leader。