1 调试配置
为了调试方便,先配置集群启动的调试面板。
1.1 调试面板
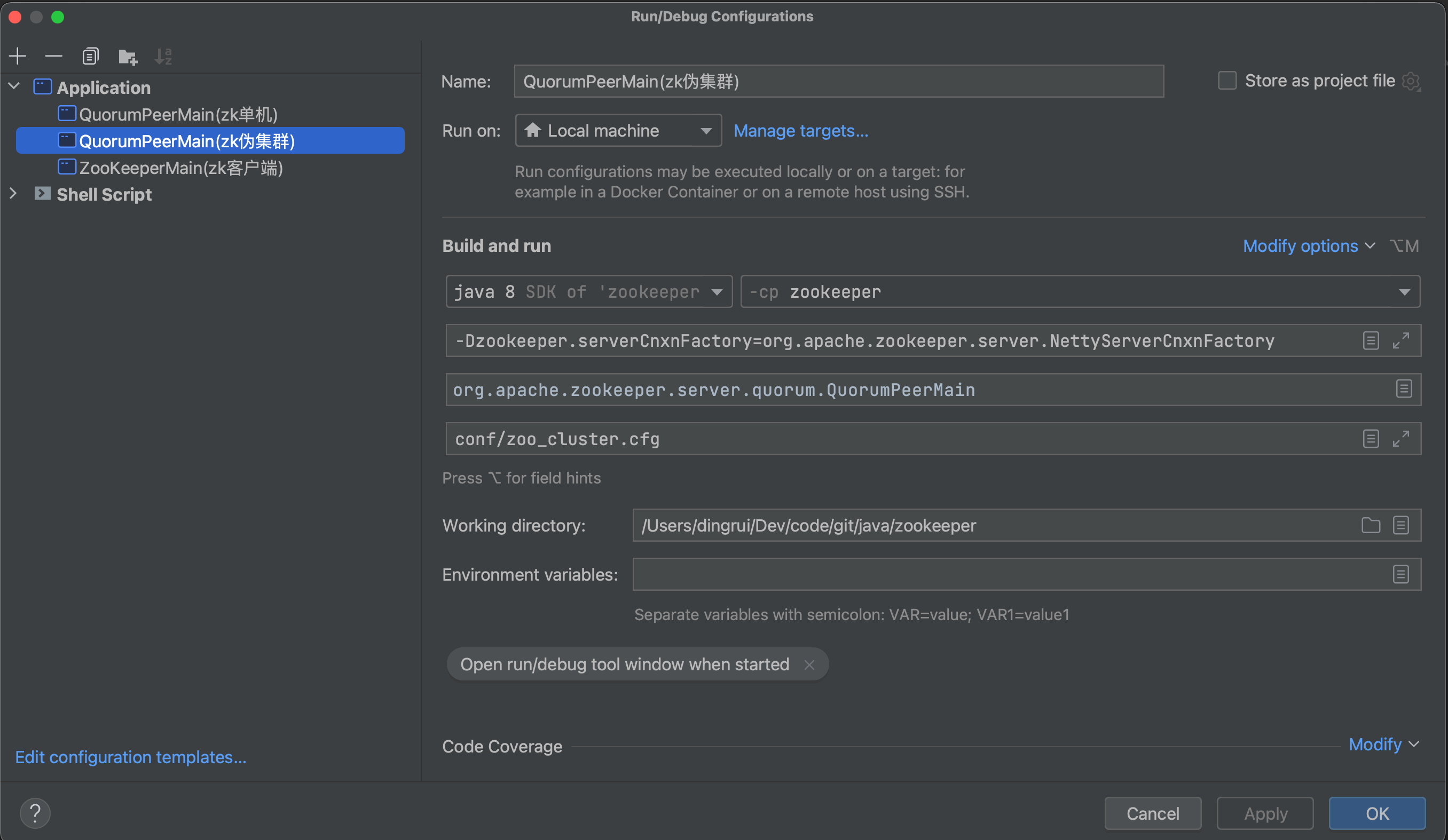
1.2 配置文件
配置文件内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| tickTime=2000
initLimit=10
syncLimit=5
# zk数据
dataDir=/tmp/zookeeper/data
# 事务日志
dataLogDir=/tmp/zookeeper/log
clientPort=2181
# 定时任务清理文件 1小时执行一次
autopurge.purgeInterval=1
# 伪集群 主机:心跳端口:数据端口
server.0=127.0.0.1:2008:6008
server.1=127.0.0.1:2007:6007
server.2=127.0.0.1:2006:6006
|
2 入口
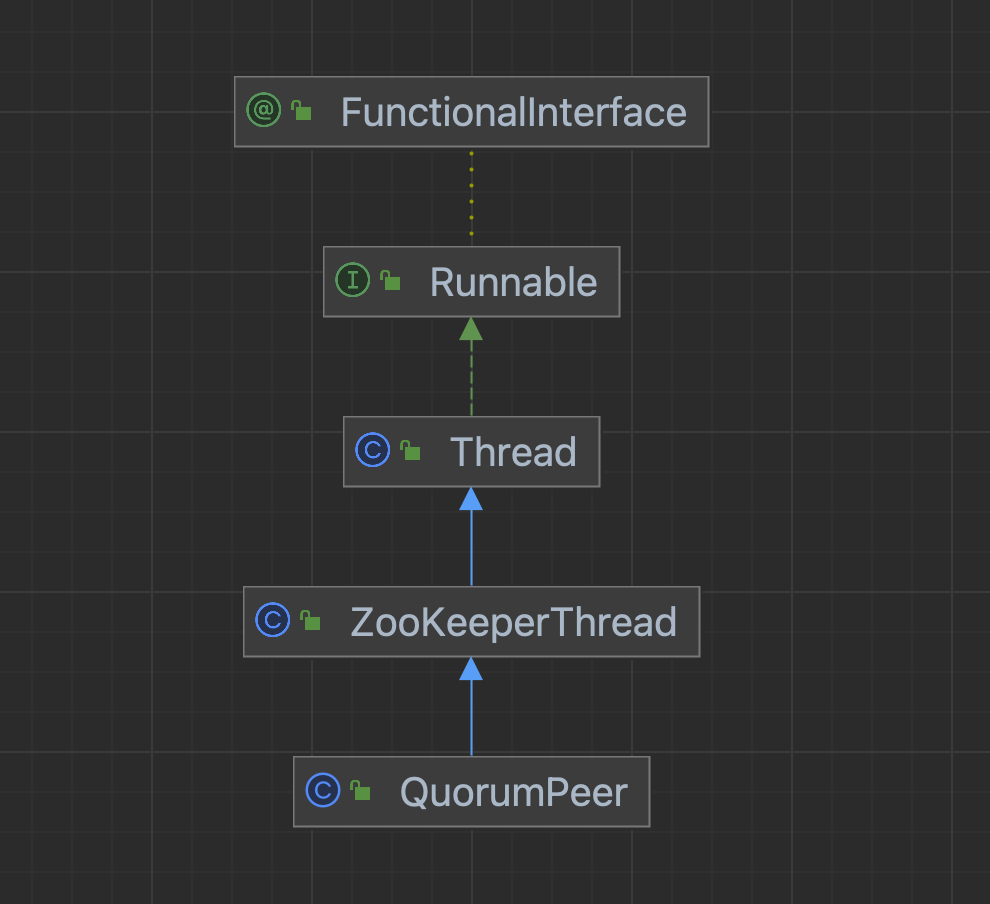
3 QuorumPeer组件
3.1 类图
从类图可以看出QuorumPeer很纯粹,就是一个Java线程,上面也分析过会在start()方法的最后调用父类的start(),最终当线程被CPU调度之后回调到当前类的run()方法,因此先看start()方法再看run()方法。
3.2 start()方法
首先,集群是单机的集合,因此之前看过的那些组件核心作用还是不会变的,这是相同点。
不同点在于:
- 集群如何选主对外提供服务
- 集群间数据如何同步
- 集群Master崩溃了如何恢复
其实也就是ZAB协议是如何实现的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| @Override
public synchronized void start() {
if (!getView().containsKey(myid)) {
throw new RuntimeException("My id " + myid + " not in the peer list");
}
loadDataBase();
startServerCnxnFactory();
try {
adminServer.start();
} catch (AdminServerException e) {
LOG.warn("Problem starting AdminServer", e);
}
startLeaderElection();
startJvmPauseMonitor();
super.start();
}
|
带着这些问题重点关注集群启动过程。
从代码可以看出:
- 集群模式中核心类是QuorumPeer,不再是ZooKeeperServer
- 依然要先加载恢复内存数据
- 额外多了一些校验
- epoch是配合集群Master角色出现的机制
- 对外客户端提供服务都是走网络,因此要前置化启动网络通信,网络通信组件依然以Netty的实现NettyServerCnxn为例,这儿监听的是2181对外暴露的端口,不是给内部节点使用的
- 选主
这些组件的使用几乎与之前分析过的一样,不一样的地方也可以直接跳过,不是重点,下面开始跟进startLeaderElection()方法。
3.3 startLeaderElection()方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
public synchronized void startLeaderElection() {
try {
if (getPeerState() == ServerState.LOOKING) {
currentVote = new Vote(myid, getLastLoggedZxid(), getCurrentEpoch());
}
} catch (IOException e) {
RuntimeException re = new RuntimeException(e.getMessage());
re.setStackTrace(e.getStackTrace());
throw re;
}
this.electionAlg = createElectionAlgorithm(electionType);
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
QuorumCnxManager qcm = createCnxnManager();
QuorumCnxManager oldQcm = qcmRef.getAndSet(qcm);
if (oldQcm != null) {
LOG.warn("Clobbering already-set QuorumCnxManager (restarting leader election?)");
oldQcm.halt();
}
QuorumCnxManager.Listener listener = qcm.listener;
if (listener != null) {
listener.start();
FastLeaderElection fle = new FastLeaderElection(this, qcm);
fle.start();
|
这个地方出现了3个组件:
3.4 run()方法
先只关注集群启动时候,当前服务器还是LOOKING状态,触发上面组件FastLeaderElection进行选主。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| case LOOKING:
LOG.info("LOOKING");
ServerMetrics.getMetrics().LOOKING_COUNT.add(1);
try {
reconfigFlagClear();
if (shuttingDownLE) {
shuttingDownLE = false;
startLeaderElection();
}
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
setPeerState(ServerState.LOOKING);
}
break;
|